🗓️ Semana 01
Introducción al curso y gestión de datos
SOC9035 – Análisis Avanzado de Datos II
09 mar 2026
Equipo Docente
Profesor

Profesor de Cátedra
Universidad Diego Portales
- Formación: Sociólogo (Universidad de Chile) y MSc en Sociología (LSE).
- Experiencia: Analista en el Observatorio Social del Ministerio de Desarrollo Social (Diseño de encuestas y producción de estadísticas oficiales).
- Intereses de investigación: Estratificación, desigualdad y sociología del trabajo.
Presentación del curso
¿De qué trata este curso?
Este curso profundiza en las técnicas de análisis multivariante, permitiendo examinar de manera integrada la interacción de múltiples factores en el estudio de problemas sociales, operando bajo los estándares de la Ciencia Abierta y la Investigación Reproducible.
Enfoque Pedagógico
Se enfatiza la toma de decisiones metodológicas, el diagnóstico de modelos y la interpretación rigurosa de los resultados, con un enfoque 100% aplicado mediante el uso de R, RStudio y Quarto.
El curso prioriza la aplicación práctica de los métodos y la evaluación crítica de literatura empírica. Al finalizar, el estudiante será capaz de:
- Analizar encuestas complejas (ej. CASEN).
- Identificar y diagnosticar la técnica estadística adecuada.
- Generar informes dinámicos que comuniquen de manera transparente los hallazgos obtenidos.
Resultados de Aprendizaje
Resultado General
Desarrollar la capacidad de aplicar técnicas de estadística multivariante descriptiva e inferencial para analizar datos, formular hipótesis y construir modelos explicativos en investigaciones sociales, asegurando la correcta interpretación teórica y la comunicación bajo estándares de investigación reproducible.
Resultados Específicos
Al finalizar el semestre, ustedes serán capaces de:
- Gestionar bases de datos sociales complejas, asegurando su limpieza y correcta aplicación de diseños muestrales (factores de expansión).
- Definir y estructurar problemas de investigación e hipótesis a partir de la lectura crítica de literatura científica.
- Seleccionar y especificar técnicas estadísticas adecuadas, justificando su aplicación empírica y teórica.
- Implementar flujos de trabajo reproducibles en R/Quarto, desarrollando la capacidad de diagnosticar y corregir modelos.
- Interpretar de forma rigurosa coeficientes, índices de ajuste y diagramas conceptuales.
- Redactar informes técnicos dinámicos, de manera clara, estructurada y transparente.
Estructura de Contenidos
1 y 2: Reproducibilidad y Muestras
💻 1. Investigación Reproducible y Datos
- Paradigma de la Ciencia Abierta en Cs. Sociales.
- Flujos de trabajo estructurados: R Projects.
- Elaboración de documentos dinámicos con
Quarto. - Repaso de
tidyverseyggplot2.
📊 2. Uso de muestras complejas en R
- Conceptos fundamentales (estratos, conglomerados).
- Diseño de encuestas (CASEN, ENUT) y ponderaciones.
- Inferencia estadística en muestras complejas.
- Manejo con los paquetes
surveyysrvyr.
3 y 4: Modelos y Regresiones
🧠 3. Introducción a Modelos Multivariados
- Rol de los modelos en las ciencias sociales.
- Diferencias entre enfoques exploratorios y confirmatorios.
- Repaso: covarianza, correlación e inferencia.
- Supuestos del análisis multivariante.
📈 4. Regresión y diseño complejo
- Relevancia del control estadístico.
- Regresión lineal múltiple.
- Integración: Estimación de modelos incorporando diseños de muestras complejas (
svyglm).
5 y 6: Análisis Factorial
🔍 5. Análisis Factorial Exploratorio (AFE)
- Aplicación en la investigación sociológica.
- Comparación entre componentes principales y factor común.
- Extracción de factores, selección y rotación.
- Matriz factorial y puntuaciones (
psych).
🎯 6. Análisis Factorial Confirmatorio (AFC)
- Diferencias principales con el AFE.
- Especificación, identificación y estimación.
- Evaluación del ajuste (CFI, RMSEA, TLI) e índices de modificación.
- Introducción al paquete
lavaan.
7 y 8: Ecuaciones Estructurales
🛤️ 7. Análisis de Sendero (Path Analysis)
- Fundamentos y diagramas causales.
- Variables endógenas y exógenas.
- Descomposición de efectos: directos, indirectos (mediación) y totales.
- Ejemplo aplicado en literatura reciente.
🏗️ 8. Modelos de Ecuaciones Estructurales (SEM)
- Integración del modelo de medida (AFC) y estructural (Path).
- Estructura, identificación y supuestos.
- Estimación, problemas de convergencia y ajuste.
- Reporte bajo estándares de publicación académica.
Bibliografía Principal
| Ítem | Título | Autor | Año |
|---|---|---|---|
| 1 | Análisis multivariable: teoría y práctica de la investigación social | Cea D’Ancona, M. A. | 2002 |
| 2 | Regression analysis and linear models: concepts and application | Darlington, R. & Hayes, A. | 2017 |
| 3 | Análisis estadístico multivariante: un enfoque teórico y práctico | De la Garza García, J. | 2013 |
| 4 | Structural equation modeling with lavaan | Gana, K. & Broc, G. | 2019 |
| 5 | El análisis factorial como técnica de investigación en psicología | Ferrando, P. & Anguiano, C. | 2010 |
| 6 | Modelos de ecuaciones estructurales | Ruiz, M.A., Pardo & San Martín | 2010 |
| 7 | El path analysis: conceptos básicos y ejemplos de aplicación | Pérez, E. et al. | 2013 |
Bibliografía Práctica y Complementaria
| Ítem | Título | Autor | Año |
|---|---|---|---|
| 8 | R para Ciencia de Datos | Wickham, H., Çetinkaya-Rundel, M. y Grolemund, G. | 2023 |
| 9 | Exploring complex survey data analysis using R ({srvyr} & {survey}) | Zimmer, S. A. et al. | 2024 |
| 10 | RStudio para estadística descriptiva en ciencias sociales | Boccardo, G. & Ruiz, F. | 2019 |
| 11 | Ciencia reproducible: qué, por qué, cómo | Rodríguez-Sánchez et al. | 2016 |
| 12 | Guía para los análisis reproducibles | LISA-COES | 2021 |
| 13 | Metodología de diseño muestral: Encuesta Casen 2022 | Min. Desarrollo Social | 2023 |
| 14 | The lavaan tutorial | Rosseel, Y. | 2017 |
Evaluaciones y Fechas Clave
El curso se evalúa mediante un sistema de hitos escalonados, uso de Quarto y evaluación crítica. La Asistencia mínima requerida es del 70% (requisito de aprobación).
| Evaluación | Ponderación | Fechas de Entrega / Rendición |
|---|---|---|
| Tarea 0 (Diagnóstico nivel R) | Formativa | 16 de marzo |
| Trabajo Final (TF): Hito 1 | 5% | 06 de abril |
| Tarea Práctica N°1 (R) | 10% | 27 de abril |
| Seminario de Lectura (Oral) | 15% | 27 de abr o 11 de may (Según grupo) |
| Trabajo Final (TF): Hito 2 | 10% | 25 de mayo |
| Prueba Solemne (Presencial) | 30% | 18 de mayo |
| Tarea Práctica N°2 (R) | 10% | 15 de junio |
| Trabajo Final (TF): Informe Final | 20% | 06 de julio (Quarto) |
Nota de eximición: 5,5 (Sin notas bajo 4,0 en la prueba solemne).
🤖 Política de Uso de IA
Esta política está inspirada en el proyecto GENIAL (LSE), que investiga con evidencia real cómo los/as estudiantes usan herramientas de IA generativa en su aprendizaje.
✅ Uso abierto y autorizado
El uso de herramientas de IA generativa (ChatGPT, Claude, Copilot, etc.) está permitido en este curso, con las siguientes condiciones:
- Junto con cada evaluación, deberán entregar un breve comentario describiendo cómo usaron (o no) la IA en su proceso de trabajo.
- Deberán adjuntar los logs o registros de sus interacciones relevantes con la IA.
🎯 ¿Por qué este requisito?
El objetivo no es fiscalizar, sino promover un uso más consciente y crítico. Al mismo tiempo, nos permite generar evidencia y conocimiento sobre cómo los/as estudiantes utilizan estas herramientas en el contexto del análisis de datos sociales.
⚠️ Excepción: Prueba Solemne y Examen
Esta política no aplica a la prueba solemne ni al examen, instancias presenciales e individuales donde no está permitido el uso de IA.
🌟 Beneficios del Uso de IA
Cuando se usan bien, las herramientas de IA pueden ser aliadas en el aprendizaje:
- Depuración de código: Identificar y corregir errores en R de manera más eficiente.
- Exploración conceptual: Solicitar explicaciones alternativas de conceptos vistos en clases.
- Retroalimentación preliminar: Obtener feedback rápido sobre la estructura de un argumento o análisis.
- Productividad: Acelerar tareas repetitivas para enfocarse en el análisis y la interpretación.
- Accesibilidad: Reducir barreras de entrada a la programación estadística.
Nota
La IA es más útil como herramienta de aprendizaje cuando ya se comprenden los fundamentos del problema que se está abordando.
⚠️ Riesgos: Aprender vs. Parecer que Aprendiste
El problema central
La IA puede generar código, análisis o textos que parecen correctos y bien escritos, sin que el/la estudiante entienda qué está haciendo. El output se ve bien, pero la comprensión no ocurrió.
Esto es especialmente riesgoso en un curso de análisis estadístico: el código puede correr sin errores y aun así no responder a los objetivos de la tarea.
El aprendizaje requiere dificultad
Aprender implica, por definición, involucrarse con lo que aún no se domina. La dificultad no es un obstáculo al aprendizaje: es su mecanismo central.
La IA puede eliminar esa dificultad… y con ello, el aprendizaje mismo.
Evidencia del proyecto GENIAL — LSE (2023-24)
En 220 estudiantes de 7 cursos, quienes usaron IA principalmente para “ir más rápido” produjeron trabajos de menor calidad. Muchos entregaron código que ejecutaba sin errores pero que no respondía a los objetivos de la tarea, sin notar la diferencia. Ver proyecto GENIAL →
Apoyo y Logística del Curso
Ayudantes del Curso

Licenciado en Sociología
📧 felipe.adasme@mail.udp.cl

Licenciada en Sociología
📧 francisca.hernandez_c@mail.udp.cl
Dinámica de las Ayudantías
- Acompañarán el progreso del curso resolviendo dudas de código, estimación de modelos y la preparación de los hitos del Trabajo Final.
Horario de Consultas
- Pueden agendar reuniones virtuales para cualquier consulta que tengan sobre el curso todos los Martes entre 16:00 y 17:00 hrs. (Virtual vía Google Meet).
- Para agendar, utiliza el siguiente enlace: https://calendar.app.google/z4iY6NKWfBEC39kR8.
Plataformas y Comunicación
🌐 Página Web del Curso
Todo el material, presentaciones y guías prácticas estarán alojados de manera centralizada en la web del curso. Guarden este enlace en sus favoritos:
🗣️ Delegado/a de Curso
Las comunicaciones con el equipo docente para temas colectivos deberán gestionarse de manera centralizada mediante un delegado o delegada, especialmente considerando que en la sala hay alumnos de distintas generaciones.
Esto es estrictamente necesario y particularmente relevante para solicitudes respecto a fechas de evaluaciones.
Gestión de Datos con Tidyverse
Objetivos de la Sesión
- Introducir el concepto de tidy data y el tidyverse como herramienta de trabajo.
- Introducir el uso de ggplot2 en R para ciencias sociales.
Proceso de Análisis de Datos

Proceso de Análisis de Datos
La ciencia de datos, y el análisis estadístico, es un proceso iterativo que puede ser resumido en los siguientes pasos:
- Importar: Traer los datos a R desde diversas fuentes (archivos, bases de datos, APIs).
- Ordenar (Tidy): Estructurar los datos de manera consistente: cada variable en una columna, cada observación en una fila.
- Transformar: Modificar los datos para responder preguntas específicas: seleccionar observaciones, crear nuevas variables, calcular resúmenes.
- Visualizar: Explorar los datos gráficamente para descubrir patrones, tendencias y anomalías.
- Modelar: Construir modelos estadísticos para confirmar patrones y realizar predicciones.
- Comunicar: Presentar los resultados de manera efectiva a diferentes audiencias.
- Programar: Utilizar la programación como herramienta transversal para automatizar tareas y resolver problemas en cada etapa.
El Tidyverse: Un Ecosistema para la Ciencia de Datos en R
El tidyverse es una colección de paquetes de R diseñados para la ciencia de datos.
- Comparte una filosofía común y facilita el trabajo con datos de manera intuitiva y eficiente.
- El nombre “tidyverse” viene de “tidy data” (datos ordenados).
- Incluye paquetes esenciales como:
dplyr,ggplot2,tidyr,readr,purrr,stringr,forcats,lubridate.
Para instalar e iniciar el tidyverse:
- Muestra los paquetes principales cargados.
- Indica posibles conflictos de funciones con otros paquetes (se pueden manejar con
conflicted).
Datos Ordenados (Tidy Data): Una Introducción
Datos ordenados (tidy data) es una manera consistente de organizar los datos.
- Facilita el análisis y la manipulación de datos con las herramientas del tidyverse.
- Aunque requiere un trabajo inicial de organización, ahorra tiempo a largo plazo al simplificar el análisis.
- Las encuestas suelen venir en este formato.
Reglas de los Datos Ordenados
Para que un conjunto de datos sea considerado ordenado, debe cumplir con tres reglas fundamentales:
- Cada variable debe tener su propia columna.
- Cada observación debe tener su propia fila.
- Cada valor debe tener su propia celda.

Ventajas de los Datos Ordenados
Trabajar con datos ordenados ofrece importantes ventajas:
- Consistencia: Facilita el aprendizaje y uso de herramientas del tidyverse, ya que están diseñadas para trabajar con este formato.
- Eficiencia en R: Permite aprovechar la naturaleza vectorizada de R, simplificando la manipulación y el análisis de datos.
- Mayor Claridad: Estructura intuitiva que facilita la comprensión de los datos y la identificación de variables y observaciones.
Al adoptar el formato tidy, optimizamos nuestro flujo de trabajo en R para el análisis de datos.
Proceso de Análisis de Datos
El sentido de cada una de estas etapas debe estar guiado por una pregunta de investigación. Sin una pregunta no podemos determinar qué datos necesitamos, en qué forma, dónde explorar y visualizar, y qué modelar y comunicar.
Tomemos un ejemplo simple: ¿Cómo se relaciona la pobreza y la ruralidad en Chile?
Importar Datos a R: Ejemplo con CASEN 2024
Para comenzar a trabajar con datos en R, el primer paso es importarlos.
Ordenar (Tidy)
Seleccionamos las variables de interés para este ejemplo: folio (identificador), area (urbana/rural), y pobreza (categorías de pobreza). Usamos select() de dplyr para elegir las columnas y head() para mostrar las primeras filas.
# A tibble: 6 × 3
folio area pobreza
<dbl> <dbl+lbl> <dbl+lbl>
1 100020301 1 [Urbano] 3 [Fuera de la pobreza]
2 100020301 1 [Urbano] 3 [Fuera de la pobreza]
3 100020401 1 [Urbano] 3 [Fuera de la pobreza]
4 100020401 1 [Urbano] 3 [Fuera de la pobreza]
5 100020401 1 [Urbano] 3 [Fuera de la pobreza]
6 100020401 1 [Urbano] 3 [Fuera de la pobreza]Transformar
Creamos una nueva variable dicotómica llamada pobrezad (pobreza dicotómica). Usamos mutate() de dplyr y ifelse() para asignar valor 1 si la variable pobreza original está en las categorías 1 o 2 (pobre o pobre extremo), y 0 en caso contrario.
Visualizar
Visualizamos la relación entre el área de residencia (area) y la pobreza dicotómica (pobrezad) usando un gráfico de barras.
casen %>%
mutate(area_label = ifelse(area == 1, "Urbana", "Rural")) %>%
group_by(area_label) %>%
summarise(porcentaje_pobre = mean(pobrezad, na.rm = TRUE) * 100) %>%
ggplot(aes(x = area_label, y = porcentaje_pobre, fill = area_label)) +
geom_col(width = 0.5, show.legend = FALSE) +
geom_text(aes(label = paste0(round(porcentaje_pobre, 1), "%")),
vjust = -0.5, size = 5, fontface = "bold") +
scale_fill_manual(values = c("Rural" = "#e67e22", "Urbana" = "#1a365d")) +
labs(title = "Porcentaje de pobreza según área de residencia",
x = "Área de Residencia",
y = "Porcentaje de Pobreza (%)") +
theme_minimal(base_size = 15)
Modelar
Modelamos la probabilidad de ser pobre (pobrezad) en función del área de residencia (area) utilizando una regresión logística. Calculamos el Odds Ratio para interpretar el efecto del área rural en comparación con el área urbana.
glm()ajusta un modelo lineal generalizado.family = "binomial"especifica la regresión logística.
summary(modelo_logistico)muestra los resultados del modelo.
exp(coef(modelo_logistico))calcula el Odds Ratio, exponenciando los coeficientes del modelo. El Odds Ratio paraarearepresenta el cambio multiplicativo en las odds de ser pobre al pasar del área urbana (referencia) al área rural.
Modelar
Call:
glm(formula = pobrezad ~ as_factor(area), family = "binomial",
data = casen)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.482402 0.006062 -244.52 <2e-16 ***
as_factor(area)Rural 0.376893 0.013332 28.27 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 216178 on 218366 degrees of freedom
Residual deviance: 215410 on 218365 degrees of freedom
AIC: 215414
Number of Fisher Scoring iterations: 4 (Intercept) as_factor(area)Rural
0.2270916 1.4577489 Comunicar
La regresión logística revela una asociación significativa y positiva entre el área de residencia rural y la pobreza. Específicamente, las personas que residen en áreas rurales tienen odds de ser pobres 1.46 veces mayores que quienes viven en áreas urbanas (p < 0,001).
Este resultado sugiere que el riesgo de pobreza es considerablemente mayor en zonas rurales de Chile, incluso en un modelo simple que solo considera el área de residencia. Este hallazgo destaca la necesidad de políticas públicas diferenciadas y focalizadas en áreas rurales para abordar eficazmente la problemática de la pobreza.
Visualización de Datos
“La visualización es una actividad humana fundamental. Una buena visualización te mostrará cosas que no esperabas o hará surgir nuevas preguntas acerca de los datos. También puede darte pistas acerca de si estás haciendo las preguntas equivocadas o si necesitas recolectar datos diferentes. Las visualizaciones pueden sorprenderte, pero no escalan particularmente bien, ya que requieren ser interpretadas por una persona.” (Wickham, 2017)
La visualización de datos resulta de gran utilidad en las distintas etapas del análisis de datos, por su capacidad de transmitirnos de manera comprensible grandes cantidades de información. Nos centraremos en su uso para análisis exploratorio y para la comunicación de resultados.
Ejemplos de visualización en Ciencias Sociales
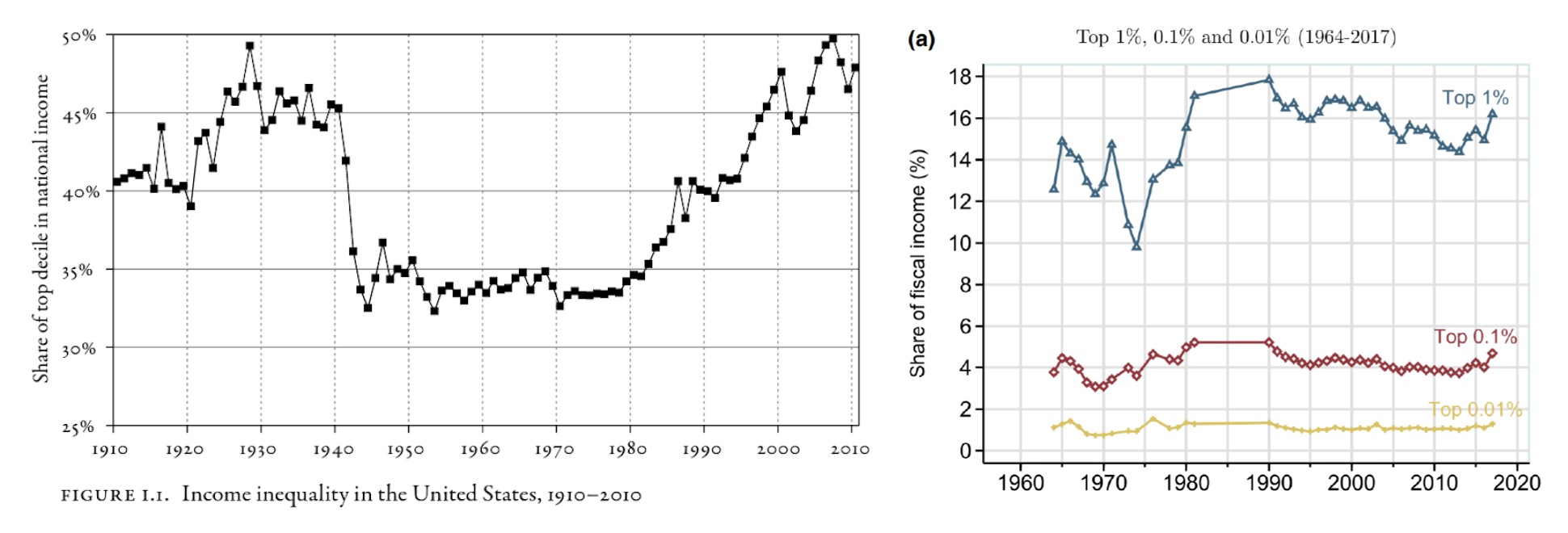
Ejemplos de visualización en Ciencias Sociales
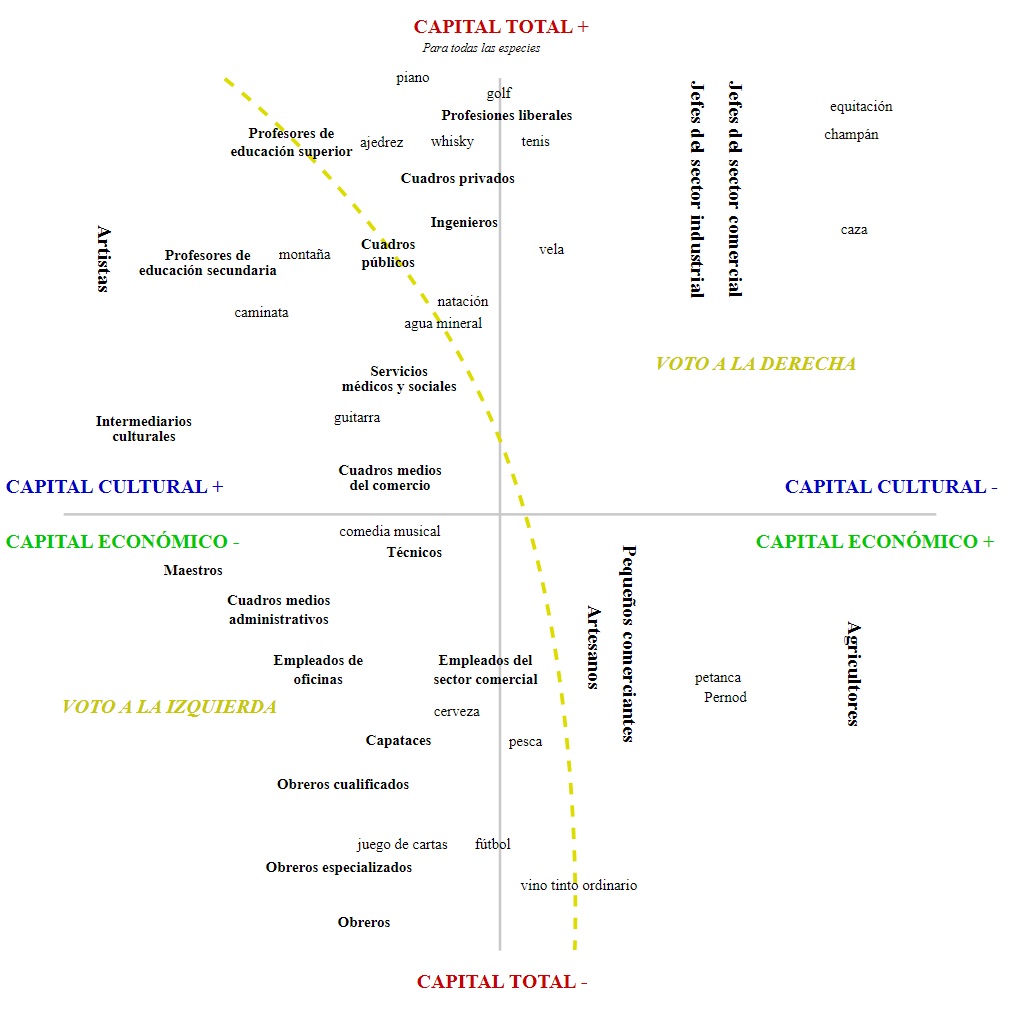
Ejemplos de las técnicas del curso
Visualización en R base
R base contiene algunas herramientas básicas de visualización de datos que nos permitirán obtener rápidamente visualizaciones de los datos para la etapa exploratoria de nuestros análisis.

Construcción de gráficos con ggplot2
La principal herramienta de visualización de datos en R es el paquete ggplot2, que forma parte de tidyverse. ggplot2 implementa la gramática de los gráficos, un sistema coherente para describir y construir gráficos.
Su versatilidad y capacidad de obtener resultados visualmente atractivos lo hacen más pertinente para tareas de presentación de resultados, tanto a públicos especializados como no especializados.
Veremos los elementos básicos para poder hacer uso del paquete más adelante en el contexto de las técnicas estadísticas a ver en el curso.
Gramática de gráficos con ggplot2
| Elemento | Descripción |
|---|---|
| Datos | Conjunto de información que se representará de manera gráfica. En nuestro caso se trata de una o más variables, a una o más observaciones. |
| Estética | Escala en la cual se posicionará la información en ejes. Refiere al posicionamiento de la información al representar sobre los diferentes ejes y dimensiones del gráfico resultante. La disposición polidimensional de variables en los ejes X y Y como también la posibilidad de indicar valores de un tercer eje, como la posición de las líneas de los diferentes ejes, o una función de transparencia, etc. |
| Geometría | Formas, elementos visuales que se emplearán para representar visualmente la información codificada en los datos y ubicada en los diferentes ejes potenciales que mencionamos en la sección anterior. Por ejemplo, puntos para representaciones de dispersión, barras para frecuencias, líneas para tendencias, etc. |
(Boccardo y Ruiz, RStudio para Estadística Descriptiva en Ciencias Sociales)
![]()
Análisis Avanzado de Datos II