
# Cargar paquetes
library(tidyverse)
library(haven)
library(survey)
library(srvyr) # ¡El paquete clave de hoy!Práctico 4: Análisis de Encuestas Complejas con srvyr
Análisis de Encuestas Complejas con srvyr
0. Objetivos del Práctico
En esta sesión, pondremos en práctica los conceptos de análisis de encuestas complejas utilizando principalmente el paquete srvyr por su sintaxis amigable estilo tidyverse. Al finalizar, podrás:
- Crear un objeto de diseño muestral (
tbl_svy) utilizandosrvyr. - Calcular estimaciones descriptivas ponderadas (medias, proporciones, totales) usando
summarisey las funcionessurvey_*. - Obtener e interpretar medidas de incertidumbre como errores estándar (SE) e intervalos de confianza (IC) para estas estimaciones.
- Realizar análisis descriptivos por subgrupos de manera eficiente usando
group_by. - Visualizar resultados ponderados utilizando
ggplot2después de calcular las estadísticas consrvyr.
1. Preparación y Declaración del Diseño con srvyr
Comenzamos cargando los paquetes necesarios y los datos de CASEN 2024 (igual que en el práctico anterior). Recuerda que los datos provienen de la Encuesta CASEN 2024, disponible en el sitio del Ministerio de Desarrollo Social y Familia. Además de tidyverse, haven y survey, ahora cargamos srvyr.
load("casen_2024.RData")
casen <- casen_2024casen <- casen %>%
mutate(pobre_dic = ifelse(pobreza %in% c(1, 2), 1, 0))Ahora, creamos el objeto de diseño tbl_svy usando srvyr::as_survey_design().
# Crear el objeto tbl_svy con srvyr
casen_design_srvyr <- as_survey_design(casen,
ids = varunit, # Variable de conglomerados (UPM)
strata = varstrat, # Variable de estratos
weights = expr ) # Variable de ponderador regional
# Inspeccionar el objeto creado con srvyr (comentado porque el output es muy largo)
#casen_design_srvyr2. Análisis Descriptivo con srvyr
Usaremos el flujo objeto_srvyr %>% summarise(...) para calcular estadísticas descriptivas ponderadas.
Medias Ponderadas
Calculemos la media de edad y escolaridad, pidiendo directamente el Intervalo de Confianza (IC) al 95% (vartype = "ci").
# Calcular medias ponderadas con IC 95%
medias_ci <- casen_design_srvyr %>%
summarise(
edad_media = survey_mean(edad, na.rm = TRUE, vartype = "ci"),
esc_media = survey_mean(esc, na.rm = TRUE, vartype = "ci")
)
medias_ciInterpretación:
La salida muestra las estimaciones ponderadas y sus intervalos de confianza al 95%.
- Edad: La edad promedio estimada para la población cubierta por CASEN 2024 es 37.9 años. Con un 95% de confianza, la verdadera edad promedio poblacional se encuentra entre 37.7 y 38 años.
- Escolaridad: La escolaridad promedio estimada es de 12.2 años. El intervalo de confianza (95%) es muy estrecho, yendo de 12.18 a 12.25 años, lo que indica una alta precisión en esta estimación.
Proporciones Ponderadas
Calcularemos la tasa de pobreza (usando pobre_dic) y la proporción por sexo.
# 1. Proporción de pobreza usando survey_mean en dummy
tasa_pobreza <- casen_design_srvyr %>%
summarise(pobreza_prop = survey_mean(pobre_dic, na.rm = TRUE, vartype = "ci"))
tasa_pobreza# 2. Proporción por sexo usando group_by + survey_prop
prop_sexo <- casen_design_srvyr %>%
mutate(sexo_factor = haven::as_factor(sexo)) %>%
group_by(sexo_factor) %>%
summarise(proporcion = survey_prop(vartype = "ci"))
prop_sexoInterpretación:
- Tasa de Pobreza: Se estima que el 17.3% de la población se encuentra en situación de pobreza (extrema o no extrema). El intervalo de confianza del 95% para esta estimación va de 16.9% a 17.7%.
- Distribución por Sexo: La población estimada se distribuye en un 49.3% de hombres (IC 95%: 49.1% - 49.6%) y un 50.7% de mujeres (IC 95%: 50.4% - 50.9%). Los intervalos estrechos reflejan una división muy cercana a la mitad en la población.
Totales Poblacionales Estimados
# Estimar el número total de personas
total_personas <- casen_design_srvyr %>%
summarise(total_pers = survey_total(vartype = "ci"))
total_personas# Estimar el número total de personas en pobreza
total_pobres <- casen_design_srvyr %>%
summarise(total_pob = survey_total(pobre_dic, na.rm = TRUE, vartype = "ci"))
total_pobresInterpretación:
- Población Total: CASEN 2024 estima una población total (cubierta por la encuesta y usando el ponderador regional
expr) de aproximadamente 20.1 millones de personas. El IC 95% sugiere que el valor real está entre 19.9 y 20.3 millones. - Total Personas Pobres: De esa población, se estima que 3,478,364 personas están en situación de pobreza. El IC 95% para este total va desde 3,391,968 hasta 3,564,760 personas.
3. Análisis por Subgrupos (group_by)
Usemos group_by() para calcular estadísticas para diferentes subgrupos.
# Media de ingreso del hogar por región (solo jefes de hogar)
ingreso_x_region <- casen_design_srvyr %>%
filter(pco1 == 1) %>%
mutate(region_factor = haven::as_factor(region)) %>%
group_by(region_factor) %>%
summarise(ingreso_medio_hogar = survey_mean(ytotcorh, na.rm = TRUE, vartype = "se"))
ingreso_x_region# Tasa de pobreza por zona (urbana/rural)
pobreza_x_zona <- casen_design_srvyr %>%
mutate(zona_factor = haven::as_factor(area)) %>%
group_by(zona_factor) %>%
summarise(tasa_pobreza = survey_mean(pobre_dic, na.rm = TRUE, vartype = "ci"))
pobreza_x_zona# Media de escolaridad por sexo
esc_x_sexo <- casen_design_srvyr %>%
mutate(sexo_factor = haven::as_factor(sexo)) %>%
group_by(sexo_factor) %>%
summarise(esc_media = survey_mean(esc, na.rm = TRUE, vartype = "ci"))
esc_x_sexoInterpretación y Reflexión:
- Ingreso por Región: La tabla muestra el ingreso medio estimado y su error estándar (SE) para cada región. Vemos diferencias: Región Metropolitana de Santiago tiene el ingreso medio estimado más alto ($2,298,437; SE $27,646), mientras que Región del Maule presenta el más bajo ($1,219,875; SE $21,225). Errores estándar más pequeños indican mayor precisión en la estimación para esa región específica.
- Pobreza por Zona: La tasa de pobreza estimada es notablemente más alta en la zona Rural (23.2%) que en la zona Urbana (16.5%). Crucialmente, los intervalos de confianza no se solapan (Rural: 22.1%-24.2%; Urbana: 16.1%-17%). Esto nos da una fuerte evidencia de que la pobreza es significativamente mayor en zonas rurales según esta encuesta.
- Escolaridad por Sexo: La escolaridad media estimada muestra una diferencia apreciable: 12.3 años para hombres (IC 95%: 12.2 - 12.3) y 12.1 años para mujeres (IC 95%: 12.1 - 12.2). Los intervalos de confianza no se solapan, lo que sugiere que la diferencia observada podría ser estadísticamente significativa (aunque para confirmarlo necesitaríamos una prueba formal).
4. Visualización de Resultados Ponderados con ggplot2
Recordatorio importante: ggplot2 no aplica automáticamente ponderadores ni calcula errores complejos. Necesita un data frame resumen con las estadísticas ya calculadas correctamente.
El flujo correcto:
- Calcular con
srvyr: Usagroup_byysummarisepara obtener las medias/proporciones y sus ICs/SEs. Guarda esto en un nuevo tibble. - Visualizar con
ggplot2: Usa ese nuevo tibble como input paraggplot.
Ejemplo: Graficar la tasa de pobreza por zona
El tibble pobreza_x_zona que calculamos en la sección anterior ya tiene exactamente la forma que necesita ggplot2. Lo usamos directamente.
ggplot(pobreza_x_zona, aes(x = zona_factor, y = tasa_pobreza, fill = zona_factor)) +
geom_col(width = 0.6) + # Gráfico de columnas
geom_errorbar(
aes(ymin = tasa_pobreza_low, ymax = tasa_pobreza_upp), # Usamos los límites del IC
width = 0.2, # Ancho de las barras de error
linewidth = 0.8 # Grosor de la línea
) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) + # Eje Y en porcentaje
# Usaremos colores específicos para Urbano/Rural si lo deseamos
# scale_fill_manual(values = c("Urbano" = "lightblue", "Rural" = "darkgreen")) +
scale_fill_viridis_d(option = "D", begin = 0.2, end = 0.7) + # Paleta Viridis (accesible)
labs(
title = "Tasa de Pobreza Estimada por Zona",
subtitle = "Encuesta CASEN 2024 (con IC 95%)",
x = "Zona Geográfica",
y = "Tasa de Pobreza Estimada",
fill = "Zona"
) +
theme_minimal(base_size = 14) +
theme(legend.position = "bottom") 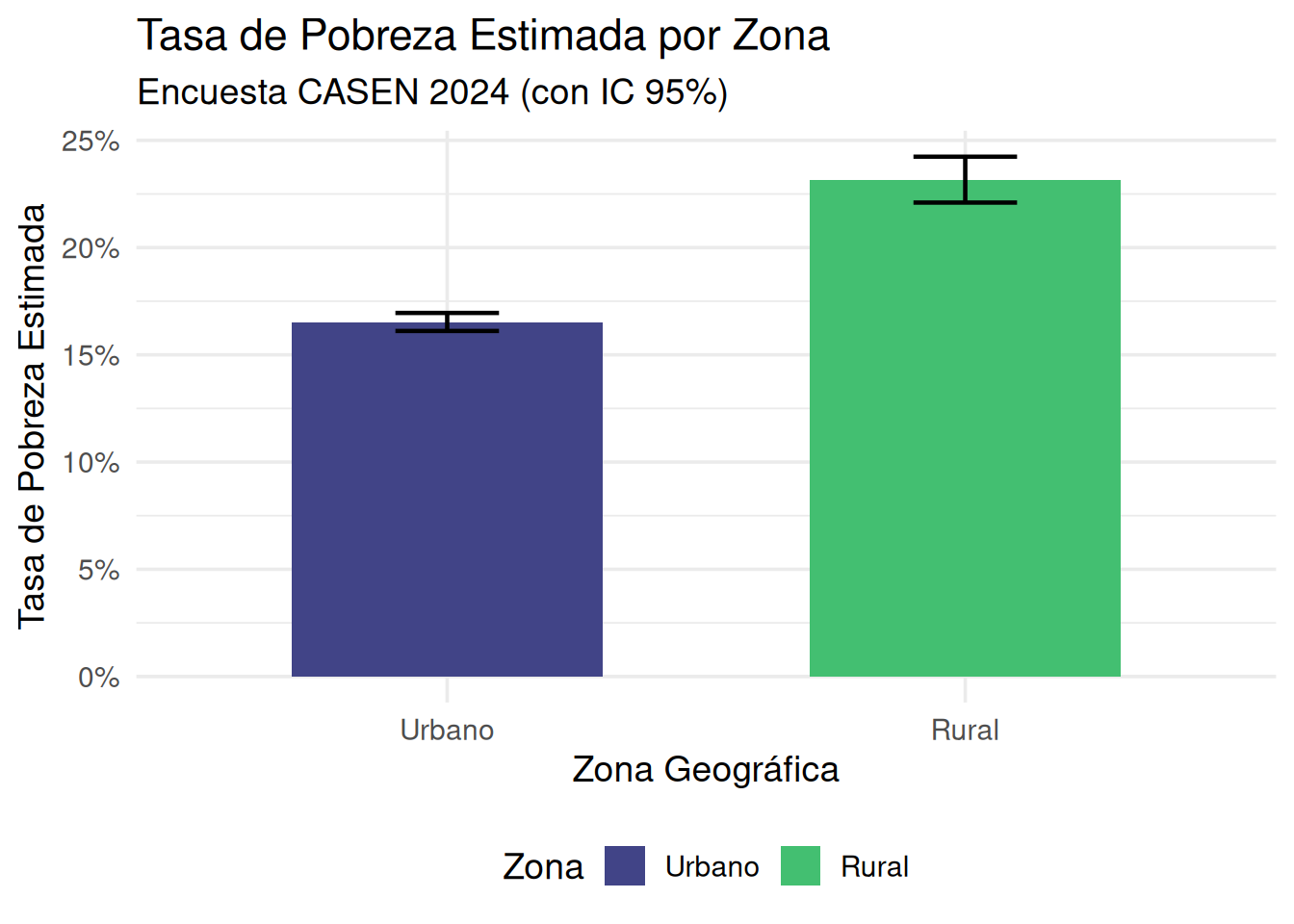
Interpretación del Gráfico: Este gráfico visualiza claramente las estimaciones de pobreza por zona calculadas previamente. Las barras muestran las tasas puntuales (mayor en Rural) y las barras de error (Intervalos de Confianza al 95%) confirman visualmente que la diferencia es significativa, ya que no hay solapamiento entre ellas. El uso de colores distintos ayuda a diferenciar las categorías.
Recuerda: Siempre calcula primero con srvyr/survey, luego visualiza con ggplot2.
5. Actividad: Estadísticas de Ingresos y Escolaridad según Orientación Sexual
En esta actividad calcularás estadísticas descriptivas para las variables de ingresos del trabajo, escolaridad y edad, desagregadas por orientación sexual, usando el módulo OSIG (Orientación Sexual e Identidad de Género) de CASEN 2024.
Contexto metodológico
El módulo OSIG es autoaplicado y solo lo responden las personas que están presentes en el hogar al momento de la encuesta. Esto implica dos consecuencias importantes:
- Factor de expansión propio: la variable
expr_osiges el ponderador específico para este módulo. Aunque los estratos (varstrat) y conglomerados (varunit) son los mismos que en el diseño general, el factor de expansión cambia. - Casos sin respuesta: quienes no tienen valor en
expr_osigno pertenecen al universo del módulo. Para un análisis válido, hay que dar por perdidos esos casos y trabajar solo con quienes tienenexpr_osigválido.
Las variables relevantes son:
| Variable | Descripción |
|---|---|
os1 |
Orientación sexual (-99=Prefiere no responder, -88=No sabe, 1=Heterosexual, 2=Gay/Lesbiana, 3=Bisexual, 4=Otra) |
expr_osig |
Factor de expansión orientación sexual e identidad de género |
ytrabajocor |
Ingreso del trabajo corregido |
esc |
Años de escolaridad |
edad |
Edad en años |
Código guía (estructura — no ejecutar)
El siguiente código es una guía estructural incompleta. Contiene las instrucciones generales y algunos huecos (...) que debes completar para resolver la actividad.
# PASO 1: Filtrar la base — conservar solo casos con expr_osig válido
casen_osig <- casen %>%
filter(!is.na(expr_osig))
# ¿Cuántos casos quedan luego del filtro?
nrow(casen_osig)
# PASO 2: Explorar la variable de orientación sexual
# Revisar categorías y decidir cómo tratar los -99 (Prefiere no responder) y -88 (No sabe)
table(casen_osig$os1, useNA = "always")
# PASO 3: Declarar el diseño muestral con el factor de expansión OSIG
# Mismos ids y strata que el diseño general, pero weights = expr_osig
casen_osig_design <- as_survey_design(
..., # <-- base de datos filtrada
ids = ..., # <-- conglomerados
strata = ..., # <-- estratos
weights = ... # <-- factor de expansión del módulo OSIG
)
# PASO 4: Calcular estadísticas de ytrabajocor, esc y edad por orientación sexual
# Recuerda filtrar las categorías -99 y -88 antes de agrupar
estadisticas_osig <- casen_osig_design %>%
mutate(os1_factor = haven::as_factor(os1)) %>%
filter(...) %>% # <-- excluir "Prefiere no responder" y "No sabe"
group_by(os1_factor) %>%
summarise(
ingreso_trabajo_medio = survey_mean(..., na.rm = TRUE, vartype = "ci"),
esc_media = survey_mean(..., na.rm = TRUE, vartype = "ci"),
edad_media = survey_mean(..., na.rm = TRUE, vartype = "ci")
)
estadisticas_osigPreguntas de interpretación
Una vez que obtengas los resultados, reflexiona sobre los siguientes puntos:
Describe las diferencias observadas en ingresos del trabajo, escolaridad y edad entre grupos de orientación sexual. ¿Los intervalos de confianza se solapan? ¿Qué implica eso?
Hipótesis: ¿A qué podrían deberse las diferencias que encuentras? Propón al menos una hipótesis alternativa a una relación “directa” entre orientación sexual e ingresos.
Interpretación con cautela: Los resultados de este cruce bivariado deben leerse con cuidado. Una diferencia en ingresos entre grupos no necesariamente refleja una relación directa: los grupos de orientación sexual pueden diferir en su composición etaria, nivel educativo, sector de inserción laboral, entre otros factores. Para aislar el efecto neto de la orientación sexual sobre los ingresos sería necesario controlar estadísticamente por esas variables — algo que abordaremos en la próxima clase con regresión lineal.
NotaNota metodológica
El módulo OSIG tiene una cobertura más limitada que el cuestionario general de CASEN, ya que solo lo responden personas presentes en el hogar. Esto introduce una posible no-respuesta diferencial que también debe tenerse en cuenta al interpretar los resultados.
6. Conclusión
En esta sesión práctica has aprendido a:
- Usar
srvyrpara declarar el diseño muestral de formatidyverse. - Calcular medias, proporciones y totales ponderados usando
summarisey las funcionessurvey_*. - Obtener e interpretar errores estándar e intervalos de confianza que reflejan el diseño complejo.
- Realizar análisis por subgrupos fácilmente con
group_by. - Visualizar correctamente los resultados ponderados usando
ggplot2después de calcular las estadísticas necesarias.
Ahora tienes las herramientas fundamentales para analizar datos de encuestas complejas como CASEN de manera rigurosa y eficiente en R, incluyendo la capacidad de crear visualizaciones informativas y correctas. El paso siguiente es aplicar estas herramientas a diferentes variables y preguntas de investigación.