
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
tidyverse,
summarytools,
psych
)Práctico 6: Análisis Factorial Exploratorio I
Preparación y Supuestos
0. Objetivo del Práctico
El objetivo de este práctico es aprender a realizar los pasos preparatorios cruciales antes de ejecutar un Análisis Factorial Exploratorio (AFE). Nos centraremos en:
- Cargar y gestionar los datos de la encuesta.
- Realizar un análisis descriptivo inicial de las variables.
- Evaluar la adecuación de los datos para el AFE:
- Tratamiento de casos perdidos.
- Identificación y manejo de casos atípicos multivariantes.
- Evaluación de la normalidad univariante y multivariante.
- Análisis de colinealidad y pruebas de factorabilidad (Bartlett y KMO).
1. Contexto: Arraigo e Integración Barrial
Trabajaremos con datos del Estudio Longitudinal Social de Chile (ELSOC), producido por el Centro de Estudios de Conflicto y Cohesión Social (COES). ELSOC hace seguimiento anual a una muestra representativa de la población chilena desde 2016, orientado al estudio del conflicto y la cohesión social.
Nos enfocaremos en el módulo de territorio y vecindario, que mide dos dimensiones teóricamente distintas del vínculo residencial:
Arraigo barrial (t02): grado en que una persona siente que el barrio le pertenece y constituye parte de su identidad.
Cohesión barrial percibida (t03): evaluación de la sociabilidad, cordialidad y disposición colaborativa de los vecinos.
Ambas dimensiones son conceptualmente distinguibles: el arraigo refiere a la relación del individuo con el lugar, mientras que la cohesión refiere a la percepción de las relaciones entre vecinos. El AFE nos permitirá examinar empíricamente si los ítems que corresponden a cada dimensión conforman factores diferenciados en los datos.
| Variable | Dimensión | Ítem |
|---|---|---|
t02_01 |
Arraigo | Este es el barrio ideal para mí |
t02_02 |
Arraigo | Me siento integrado/a en este barrio |
t02_03 |
Arraigo | Me identifico con la gente de este barrio |
t02_04 |
Arraigo | Este barrio es parte de mí |
t03_01 |
Cohesión | En este barrio es fácil hacer amigos |
t03_02 |
Cohesión | La gente en este barrio es sociable |
t03_03 |
Cohesión | La gente en este barrio es cordial |
t03_04 |
Cohesión | La gente en este barrio es colaboradora |
Todos los ítems se responden en una escala de 1 (Totalmente en desacuerdo) a 5 (Totalmente de acuerdo).
2. Configuración del Proyecto y Datos
Proyecto de R
Para mantener el trabajo ordenado, crea un Proyecto de R (.Rproj) en la carpeta de este práctico: Archivo → Nuevo Proyecto → Directorio Existente. Esto garantiza que las rutas relativas funcionen correctamente y que el entorno de trabajo sea reproducible.
Descarga de datos
Los datos de ELSOC están disponibles en el repositorio Dataverse de Harvard:
👉 Descargar ELSOC_Long_2016_2023.RData
Descarga el archivo .RData y guárdalo en la carpeta raíz de tu proyecto (la misma donde está el archivo .Rproj).
Carga de paquetes y datos
# Carga el archivo desde la carpeta raíz de tu proyecto
load("ELSOC_Long_2016_2023.RData")datos <- elsoc_long_2016_2023 %>%
filter(ola == 7) %>%
select(
idencuesta,
arraigo1 = t02_01,
arraigo2 = t02_02,
arraigo3 = t02_03,
arraigo4 = t02_04,
cohesion1 = t03_01,
cohesion2 = t03_02,
cohesion3 = t03_03,
cohesion4 = t03_04,
sexo = m0_sexo,
edad = m0_edad,
educ = m01,
region = region_cod
)
glimpse(datos)Rows: 2,726
Columns: 13
$ idencuesta <dbl> 3101131, 4301182, 13605132, 8305022, 7404033, 9102041, 3101…
$ arraigo1 <dbl> 4, 4, 2, 4, 4, 4, 4, 4, 5, 2, 4, 4, 4, 4, 4, 5, 4, 3, 4, 3,…
$ arraigo2 <dbl> 4, 4, 2, 4, 4, 4, 4, 4, 5, 4, 4, 3, 4, 4, 3, 5, 4, 3, 4, 4,…
$ arraigo3 <dbl> 4, 4, 3, 5, 4, 4, 4, 3, 5, 4, 4, 4, 2, 4, 4, 5, 4, 3, 4, 5,…
$ arraigo4 <dbl> 4, 4, 4, 5, 4, 4, 4, 4, 5, 4, 5, 4, 2, 4, 3, 5, 4, 4, 3, 5,…
$ cohesion1 <dbl> 4, 3, 2, 5, 3, 4, 4, 2, 5, 3, 4, 4, 1, 4, 2, 5, 3, 3, 4, 5,…
$ cohesion2 <dbl> 4, 3, 4, 4, 2, 4, 4, 2, 5, 4, 4, 4, 3, 4, 3, 5, 4, 3, 5, 5,…
$ cohesion3 <dbl> 4, 3, 4, 4, 4, 4, 4, 2, 5, 3, 5, 4, 3, 4, 3, 5, 4, 3, 5, 5,…
$ cohesion4 <dbl> 4, 3, 3, 5, 4, 4, 4, 2, 4, 4, 5, 4, 3, 4, 4, 5, 4, 3, 4, 4,…
$ sexo <dbl> 1, 2, 2, 1, 2, 1, 2, 1, 2, 2, 2, 1, 2, 2, 2, 1, 2, 2, 1, 1,…
$ edad <dbl> 68, 43, 27, 79, 72, 66, 37, 33, 68, 46, 47, 64, 65, 49, 79,…
$ educ <dbl> 7, 5, 9, 4, 5, 2, 5, 4, 2, 3, 7, 3, 5, 5, 3, 2, 9, 5, 5, 4,…
$ region <dbl> 3, 4, 13, 8, 7, 9, 3, 7, 5, 8, 5, 16, 13, 9, 7, 5, 8, 5, 11…Tratamiento de Valores Perdidos
ELSOC codifica las no-respuestas con valores especiales: -888 (No sabe), -999 (No responde) y -777 (No aplica). Los convertimos a NA.
summary(datos[, 2:9]) arraigo1 arraigo2 arraigo3 arraigo4
Min. :-999.000 Min. :1.000 Min. :-999.000 Min. :-999.000
1st Qu.: 3.000 1st Qu.:3.000 1st Qu.: 3.000 1st Qu.: 3.000
Median : 4.000 Median :4.000 Median : 4.000 Median : 4.000
Mean : 2.646 Mean :3.722 Mean : 2.878 Mean : 3.353
3rd Qu.: 4.000 3rd Qu.:4.000 3rd Qu.: 4.000 3rd Qu.: 4.000
Max. : 5.000 Max. :5.000 Max. : 5.000 Max. : 5.000
cohesion1 cohesion2 cohesion3 cohesion4
Min. :-888.000 Min. :-999.000 Min. :-888.00 Min. :-999.000
1st Qu.: 3.000 1st Qu.: 3.000 1st Qu.: 3.00 1st Qu.: 3.000
Median : 4.000 Median : 4.000 Median : 4.00 Median : 4.000
Mean : 0.759 Mean : 2.557 Mean : 3.36 Mean : -1.376
3rd Qu.: 4.000 3rd Qu.: 4.000 3rd Qu.: 4.00 3rd Qu.: 4.000
Max. : 5.000 Max. : 5.000 Max. : 5.00 Max. : 5.000 datos <- datos %>%
mutate(across(starts_with(c("arraigo", "cohesion")),
~ ifelse(.x %in% c(-777, -888, -999), NA, .x)))
summary(datos[, 2:9]) arraigo1 arraigo2 arraigo3 arraigo4
Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.000
Median :4.000 Median :4.000 Median :4.000 Median :4.000
Mean :3.708 Mean :3.722 Mean :3.614 Mean :3.721
3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000
NA's :3 NA's :2 NA's :1
cohesion1 cohesion2 cohesion3 cohesion4
Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.000
Median :4.000 Median :4.000 Median :4.000 Median :4.000
Mean :3.375 Mean :3.579 Mean :3.687 Mean :3.571
3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000
NA's :8 NA's :3 NA's :1 NA's :15 Análisis Descriptivo Inicial
print(dfSummary(datos[, 2:9], headings = FALSE, method = "render",
graph.magnif = 0.8))| No | Variable | Stats / Values | Freqs (% of Valid) | Graph | Valid | Missing |
|---|---|---|---|---|---|---|
| 1 | arraigo1 [numeric] | Mean (sd) : 3.7 (1) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 77 ( 2.8%) 2 : 297 (10.9%) 3 : 399 (14.7%) 4 : 1520 (55.8%) 5 : 430 (15.8%) | II II IIIIIIIIIII III | 2723 (99.9%) | 3 (0.1%) |
| 2 | arraigo2 [numeric] | Mean (sd) : 3.7 (0.9) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.2) | 1 : 61 ( 2.2%) 2 : 288 (10.6%) 3 : 407 (14.9%) 4 : 1562 (57.3%) 5 : 408 (15.0%) | II II IIIIIIIIIII II | 2726 (100.0%) | 0 (0.0%) |
| 3 | arraigo3 [numeric] | Mean (sd) : 3.6 (1) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 65 ( 2.4%) 2 : 361 (13.3%) 3 : 497 (18.2%) 4 : 1439 (52.8%) 5 : 362 (13.3%) | II III IIIIIIIIII II | 2724 (99.9%) | 2 (0.1%) |
| 4 | arraigo4 [numeric] | Mean (sd) : 3.7 (0.9) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 65 ( 2.4%) 2 : 300 (11.0%) 3 : 401 (14.7%) 4 : 1523 (55.9%) 5 : 436 (16.0%) | II II IIIIIIIIIII III | 2725 (100.0%) | 1 (0.0%) |
| 5 | cohesion1 [numeric] | Mean (sd) : 3.4 (1) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 91 ( 3.3%) 2 : 550 (20.2%) 3 : 591 (21.7%) 4 : 1221 (44.9%) 5 : 265 ( 9.7%) | IIII IIII IIIIIIII I | 2718 (99.7%) | 8 (0.3%) |
| 6 | cohesion2 [numeric] | Mean (sd) : 3.6 (0.9) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 53 ( 1.9%) 2 : 364 (13.4%) 3 : 545 (20.0%) 4 : 1475 (54.2%) 5 : 286 (10.5%) | II IIII IIIIIIIIII II | 2723 (99.9%) | 3 (0.1%) |
| 7 | cohesion3 [numeric] | Mean (sd) : 3.7 (0.9) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.2) | 1 : 41 ( 1.5%) 2 : 274 (10.1%) 3 : 494 (18.1%) 4 : 1604 (58.9%) 5 : 312 (11.4%) | II III IIIIIIIIIII II | 2725 (100.0%) | 1 (0.0%) |
| 8 | cohesion4 [numeric] | Mean (sd) : 3.6 (0.9) min < med < max: 1 < 4 < 5 IQR (CV) : 1 (0.3) | 1 : 49 ( 1.8%) 2 : 395 (14.6%) 3 : 558 (20.6%) 4 : 1377 (50.8%) 5 : 332 (12.2%) | II IIII IIIIIIIIII II | 2711 (99.4%) | 15 (0.6%) |
Interpretación:
- Todos los ítems varían en el rango esperado (1–5). Las medias se sitúan entre 3.4 y 3.7, con desviaciones estándar de aproximadamente 0.9–1.0 en todos los casos: las distribuciones son similares en forma y dispersión entre dimensiones.
- Dentro del bloque de arraigo, los ítems
arraigo1,arraigo2yarraigo4presentan la media más alta (M=3.7), mientras quearraigo3(“Me identifico con la gente”) es algo más baja (M=3.6) y muestra mayor porcentaje en las categorías intermedias (18% responde 3). - Dentro del bloque de cohesión,
cohesion1(“En este barrio es fácil hacer amigos”) es notablemente más baja (M=3.4): el 20% responde 2 y solo el 9.7% responde 5, lo que indica que la facilidad para hacer amigos es la dimensión de la cohesión percibida menos favorable. Los ítemscohesion3(“cordial”) ycohesion2(“sociable”) son algo más altos (M=3.7 y 3.6 respectivamente). - En promedio, ambos bloques presentan medias comparables (~3.6–3.7); no hay una diferencia sistemática entre arraigo y cohesión en nivel.
- Los valores perdidos son mínimos: el ítem con más pérdida es
cohesion4(15 casos, 0.6%), todos los demás están por debajo del 0.3%.
3. Comprobación de Supuestos para AFE
Eliminación Listwise
Creamos una base sin valores perdidos en los 8 ítems para los tests que lo requieren.
n_original <- nrow(datos)
datosLW <- datos %>%
select(starts_with(c("arraigo", "cohesion"))) %>%
na.omit()
n_original - nrow(datosLW) # Casos eliminados[1] 29nrow(datosLW) # Casos para el análisis[1] 2697Interpretación: Se eliminan solo 29 casos (1.1% de los 2,726 de ola 7), quedando 2,697. La pérdida es mínima y no compromete el análisis. Si fuera mayor al 10% o con patrón sistemático (p. ej., más pérdida en grupos específicos), se consideraría imputación múltiple.
Casos Atípicos Multivariantes (Distancia de Mahalanobis)
n_vars <- ncol(datosLW)
mean_vars <- colMeans(datosLW)
Sx_cov <- cov(datosLW)
D2 <- mahalanobis(datosLW, center = mean_vars, cov = Sx_cov)
datosLW$p_mah <- 1 - pchisq(D2, df = n_vars)
sum(datosLW$p_mah < 0.001) # Número de atípicos identificados[1] 86datosLW <- datosLW %>%
filter(p_mah > 0.001) %>%
select(-p_mah)
nrow(datosLW) # Casos finales[1] 2611Interpretación: Se identifican 86 casos atípicos multivariantes (3.2% de los 2,697 listwise), quedando 2,611 para el AFE. La distancia de Mahalanobis D² mide cuánto se aleja cada caso del perfil de respuesta típico considerando la covarianza entre los 8 ítems; bajo distribución chi-cuadrado con df=8, el umbral p<0.001 es conservador y selecciona solo los perfiles más extremos.
Normalidad Multivariante (Test de Mardia)
psych::mardia(datosLW, plot = TRUE)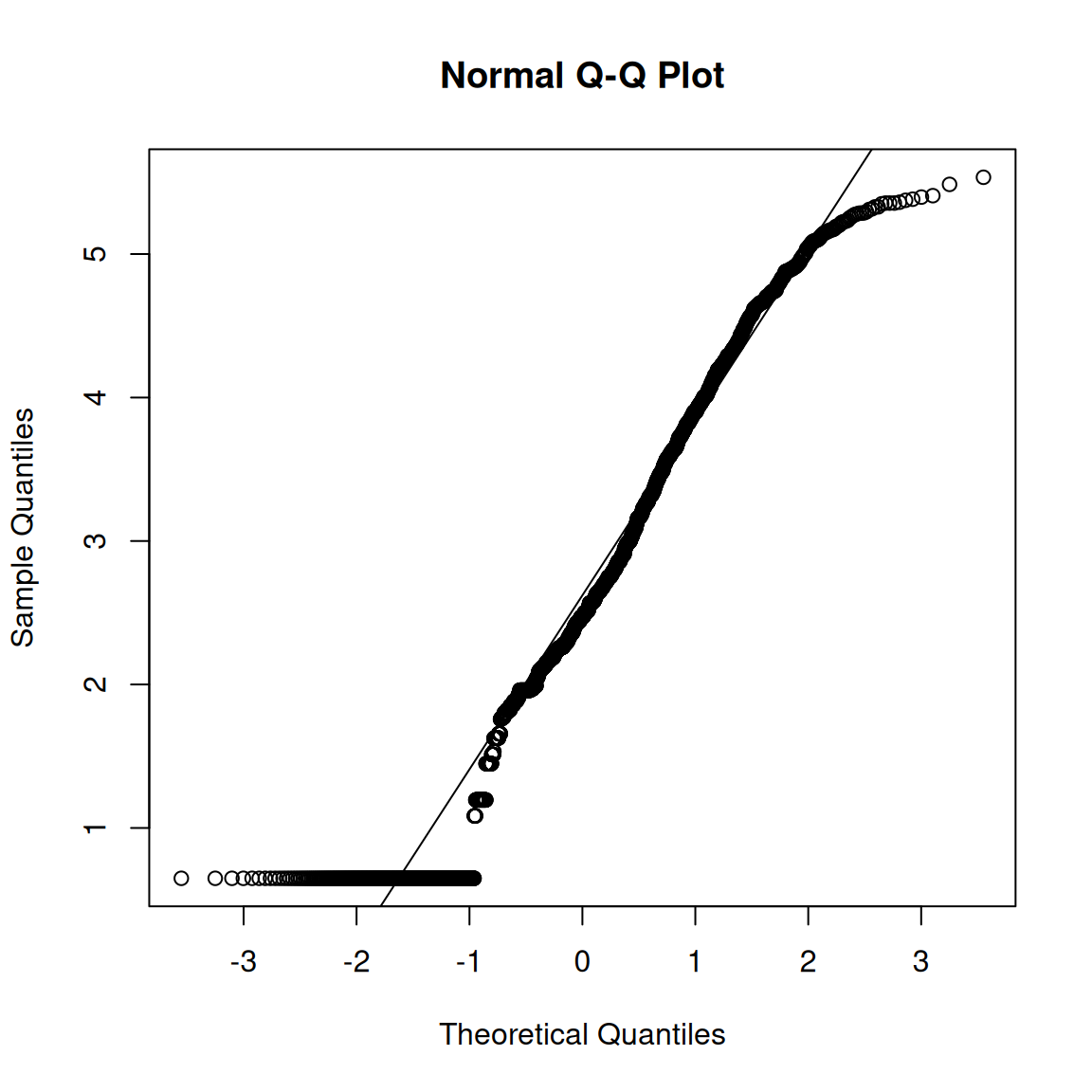
Call: psych::mardia(x = datosLW, plot = TRUE)
Mardia tests of multivariate skew and kurtosis
Use describe(x) the to get univariate tests
n.obs = 2611 num.vars = 8
b1p = 6.09 skew = 2648.32 with probability <= 0
small sample skew = 2652.04 with probability <= 0
b2p = 110.12 kurtosis = 60.84 with probability <= 0# P-valores del test de Shapiro-Wilk por variable
sapply(datosLW, function(x) shapiro.test(x)$p.value) |> round(4) arraigo1 arraigo2 arraigo3 arraigo4 cohesion1 cohesion2 cohesion3 cohesion4
0 0 0 0 0 0 0 0 Interpretación:
- El test de Mardia rechaza la normalidad multivariante: la asimetría multivariante (b1p=6.09, p≈0) y la curtosis (b2p=110.12, estadístico=60.84, p≈0) son ambas significativas. El gráfico Q-Q chi-cuadrado muestra desviación notable de la línea diagonal, especialmente en las colas.
- El test de Shapiro-Wilk rechaza la normalidad en las 8 variables (p<0.001 en todos los casos), lo cual es previsible: los ítems Likert de 5 categorías con distribuciones concentradas en las categorías 3-4 no pueden seguir una distribución normal.
- Implicaciones para el AFE:
- Preferiremos
fm = "minres"(mínimos cuadrados residuales) sobre Máxima Verosimilitud, que supone normalidad. - Usaremos correlaciones policóricas en lugar de Pearson, más adecuadas para variables ordinales.
- El test de Bartlett debe interpretarse solo de forma orientativa.
- Preferiremos
Matriz de Correlaciones de Pearson
cor_datos <- cor(datosLW)
round(cor_datos, 2) arraigo1 arraigo2 arraigo3 arraigo4 cohesion1 cohesion2 cohesion3
arraigo1 1.00 0.67 0.63 0.66 0.40 0.38 0.46
arraigo2 0.67 1.00 0.73 0.69 0.52 0.50 0.55
arraigo3 0.63 0.73 1.00 0.71 0.55 0.53 0.56
arraigo4 0.66 0.69 0.71 1.00 0.50 0.46 0.49
cohesion1 0.40 0.52 0.55 0.50 1.00 0.66 0.57
cohesion2 0.38 0.50 0.53 0.46 0.66 1.00 0.70
cohesion3 0.46 0.55 0.56 0.49 0.57 0.70 1.00
cohesion4 0.37 0.48 0.50 0.44 0.51 0.58 0.62
cohesion4
arraigo1 0.37
arraigo2 0.48
arraigo3 0.50
arraigo4 0.44
cohesion1 0.51
cohesion2 0.58
cohesion3 0.62
cohesion4 1.00det(cor_datos) # Determinante: cercano a 0 = alta colinealidad (deseable)[1] 0.007462152Interpretación:
- Todas las correlaciones son positivas y sustanciales. Las correlaciones dentro del bloque de arraigo oscilan entre 0.63 y 0.73 (la más alta:
arraigo2–arraigo3= 0.73). Las correlaciones dentro del bloque de cohesión oscilan entre 0.51 y 0.70 (la más alta:cohesion2–cohesion3= 0.70). Las correlaciones entre bloques son menores, situándose entre 0.37 y 0.55: el par con mayor correlación cruzada esarraigo2–cohesion3(0.55). - Este patrón — correlaciones intra-bloque mayores que inter-bloque — anticipa la existencia de dos factores diferenciados que corresponden a las dos dimensiones teóricas.
- El determinante de la matriz es 0.0075, muy cercano a cero, confirmando la alta colinealidad necesaria para el AFE.
Matriz de Correlaciones Policóricas
matriz_policorica <- polychoric(datosLW)
round(matriz_policorica$rho, 2) arraigo1 arraigo2 arraigo3 arraigo4 cohesion1 cohesion2 cohesion3
arraigo1 1.00 0.75 0.71 0.74 0.47 0.47 0.55
arraigo2 0.75 1.00 0.82 0.78 0.60 0.59 0.63
arraigo3 0.71 0.82 1.00 0.79 0.63 0.61 0.64
arraigo4 0.74 0.78 0.79 1.00 0.58 0.55 0.58
cohesion1 0.47 0.60 0.63 0.58 1.00 0.75 0.67
cohesion2 0.47 0.59 0.61 0.55 0.75 1.00 0.80
cohesion3 0.55 0.63 0.64 0.58 0.67 0.80 1.00
cohesion4 0.45 0.57 0.59 0.53 0.59 0.68 0.72
cohesion4
arraigo1 0.45
arraigo2 0.57
arraigo3 0.59
arraigo4 0.53
cohesion1 0.59
cohesion2 0.68
cohesion3 0.72
cohesion4 1.00Interpretación: Las correlaciones policóricas son sistemáticamente más altas que las de Pearson: las intra-bloque de arraigo pasan a un rango de 0.71–0.82 (vs. 0.63–0.73 en Pearson) y las de cohesión a 0.59–0.80 (vs. 0.51–0.70). Las correlaciones entre bloques también suben, pero menos (rango 0.45–0.63), de modo que la diferenciación entre bloques se mantiene con claridad. La correlación más alta en toda la matriz es arraigo2–arraigo3 = 0.82. Esta matriz será la base del AFE en el Práctico 7.
Factorabilidad: Bartlett y KMO
cortest.bartlett(cor_datos, n = nrow(datosLW))$chisq
[1] 12766.41
$p.value
[1] 0
$df
[1] 28KMO(datosLW)Kaiser-Meyer-Olkin factor adequacy
Call: KMO(r = datosLW)
Overall MSA = 0.91
MSA for each item =
arraigo1 arraigo2 arraigo3 arraigo4 cohesion1 cohesion2 cohesion3 cohesion4
0.91 0.91 0.91 0.91 0.92 0.87 0.89 0.93 Interpretación:
- Bartlett: χ²=12,766.41 con 28 grados de libertad y p≈0 indica que la matriz de correlaciones difiere significativamente de la identidad, es decir, hay correlaciones sustanciales entre los ítems. Dado el incumplimiento de normalidad, este resultado es orientativo.
- KMO global = 0.91, clasificado como “meritorio” según Kaiser (1974). Los KMOs individuales oscilan entre 0.87 (
cohesion2) y 0.93 (cohesion4), todos muy por encima del umbral mínimo de 0.50. Esto indica que cada ítem comparte una cantidad sustancial de varianza con los demás y contribuye bien a la estructura factorial común.
Conclusión: A pesar de la falta de normalidad multivariante —esperable en ítems Likert de 5 categorías—, las altas intercorrelaciones, el determinante cercano a cero y el KMO=0.91 indican que los datos son adecuados para el AFE. El próximo práctico completa el análisis.
4. Síntesis y Próximos Pasos
Con los datos preparados, los próximos pasos en el Práctico 7 serán:
- Determinar el número de factores (Scree Plot y Análisis Paralelo).
- Extraer factores con correlaciones policóricas y
fm = "minres". - Comparar rotaciones Varimax y Promax.
- Interpretar y nombrar los factores.
- Calcular puntuaciones factoriales y explorar diferencias por grupos.