
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
haven, # importar datos SPSS/Stata
lavaan, # AFC y SEM
dplyr, # manipulación de datos
semPlot, # visualización de modelos SEM
texreg # tablas de resultados
)Práctico 8: Análisis Factorial Confirmatorio (AFC)
AFC con lavaan
0. Objetivos del Práctico
En este práctico, aprenderemos a realizar un Análisis Factorial Confirmatorio (AFC) utilizando el paquete lavaan en R. El AFC nos permite testear una estructura factorial hipotetizada previamente, basada en la teoría o en resultados de un AFE. Al finalizar, serás capaz de:
- Especificar un modelo de medición AFC en la sintaxis de
lavaan. - Estimar los parámetros del modelo.
- Evaluar el ajuste global del modelo utilizando índices como χ², RMSEA, CFI y TLI, entendiendo sus limitaciones como heurísticos.
- Evaluar el ajuste local mediante la matriz de residuos de correlación para detectar discrepancias a nivel de pares de ítems.
- Interpretar las cargas factoriales estandarizadas y no estandarizadas.
- Calcular e interpretar las comunalidades (R² de los indicadores).
- Explorar los índices de modificación con sentido crítico, evitando la capitalización del azar.
1. Carga de Paquetes y Datos
Primero, cargamos los paquetes necesarios. lavaan es el paquete central para AFC y SEM. semPlot (si está disponible) nos permitirá visualizar el modelo.
A continuación, importamos los datos. Usaremos una base de ejemplo sobre ideología que contiene ítems para medir “autoritarismo” y “dominancia social”.
| Item | Etiqueta |
|---|---|
| dom1 | Los grupos inferiores debieran quedarse en su lugar |
| dom2 | Si algunos grupos se mantuvieran en su lugar, tendríamos menos problemas |
| dom3 | A veces es necesario pasar por encima de algunos grupos para surgir en la vida |
| aut1 | Las formas y valores tradicionales aún son la mejor manera de vivir |
| aut2 | Es importante que mantengamos los valores y estándares morales tradicionales |
| aut3 | Este país va a prosperar si los jóvenes dejan de experimentar con drogas, alcohol y sexo, y prestan más atención a los valores familiares |
# Importar datos desde una URL (GitHub)
datos <- read_sav(url("https://github.com/Clases-GabrielSotomayor/pruebapagina/raw/master/content/example/input/data/base_ideologia_afc.sav"))
# Vistazo rápido a los datos y sus nombres
# glimpse(datos) # Comentado para brevedad
# head(datos) # Comentado para brevedad2. Especificación del Modelo de Medición
Definimos nuestro modelo teórico. Hipotetizamos dos factores latentes: * autoritarismo: medido por los ítems aut1, aut2, aut3. * dominancia: medido por los ítems dom1, dom2, dom3.
En la sintaxis de lavaan, el operador =~ (“es medido por”) define esta relación.
# Definir el modelo de medición para el AFC
mod_conf <- '
# Factor latente de Autoritarismo y sus indicadores
autoritarismo =~ aut1 + aut2 + aut3
# Factor latente de Dominancia Social y sus indicadores
dominancia =~ dom1 + dom2 + dom3
# Por defecto, lavaan estima la covarianza entre factores latentes si hay más de uno.
'
# Imprimimos la especificación para verificar
# cat(mod_conf) # Comentado para brevedad3. Estimación del Modelo AFC
Con el modelo especificado, usamos la función cfa() de lavaan para estimar los parámetros.
# Ajustar el modelo AFC a los datos
mod_conf_afc <- cfa(model = mod_conf, data = datos)El objeto mod_conf_afc ahora contiene todos los resultados de la estimación.
4. Evaluación de los Resultados del Modelo
Usamos summary() para obtener un resumen completo, solicitando medidas de ajuste y soluciones estandarizadas.
# Obtener un resumen completo del modelo ajustado
summary_output <- summary(mod_conf_afc,
standardized = TRUE, # Mostrar cargas estandarizadas (Std.all)
fit.measures = TRUE, # Mostrar un conjunto extendido de índices de ajuste
rsquare = TRUE) # Mostrar R-cuadrado para variables observadas (comunalidades)
print(summary_output)lavaan 0.6-21 ended normally after 29 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 13
Number of observations 176
Model Test User Model:
Test statistic 12.332
Degrees of freedom 8
P-value (Chi-square) 0.137
Model Test Baseline Model:
Test statistic 650.010
Degrees of freedom 15
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.993
Tucker-Lewis Index (TLI) 0.987
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -1682.172
Loglikelihood unrestricted model (H1) NA
Akaike (AIC) 3390.345
Bayesian (BIC) 3431.561
Sample-size adjusted Bayesian (SABIC) 3390.393
Root Mean Square Error of Approximation:
RMSEA 0.055
90 Percent confidence interval - lower 0.000
90 Percent confidence interval - upper 0.113
P-value H_0: RMSEA <= 0.050 0.384
P-value H_0: RMSEA >= 0.080 0.282
Standardized Root Mean Square Residual:
SRMR 0.049
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
autoritarismo =~
aut1 1.000 1.646 0.907
aut2 0.921 0.060 15.457 0.000 1.517 0.887
aut3 0.929 0.069 13.502 0.000 1.530 0.803
dominancia =~
dom1 1.000 1.201 0.919
dom2 1.096 0.080 13.729 0.000 1.316 0.882
dom3 0.861 0.084 10.298 0.000 1.034 0.685
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
autoritarismo ~~
dominancia 0.678 0.174 3.891 0.000 0.343 0.343
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.aut1 0.582 0.129 4.504 0.000 0.582 0.177
.aut2 0.623 0.117 5.319 0.000 0.623 0.213
.aut3 1.291 0.170 7.598 0.000 1.291 0.356
.dom1 0.264 0.083 3.181 0.001 0.264 0.155
.dom2 0.494 0.108 4.585 0.000 0.494 0.222
.dom3 1.209 0.142 8.484 0.000 1.209 0.531
autoritarismo 2.711 0.364 7.454 0.000 1.000 1.000
dominancia 1.442 0.196 7.360 0.000 1.000 1.000
R-Square:
Estimate
aut1 0.823
aut2 0.787
aut3 0.644
dom1 0.845
dom2 0.778
dom3 0.469Interpretación de la Salida de summary():
- Encabezado:
lavaan 0.6-21 ended normally after 29 iterations. El modelo convergió sin problemas. Se usó el estimadorML(Máxima Verosimilitud) con N = 176. Latent Variables:autoritarismo =~:aut1: Carga no estandarizada fijada a 1.000 (restricción de identificación). Carga estandarizada (Std.all) = 0.907.aut2: Carga estandarizada (Std.all) = 0.887; significativa (p < 0.001).aut3: Carga estandarizada (Std.all) = 0.803; significativa (p < 0.001).- Los tres indicadores tienen cargas superiores a 0.80 y todas son significativas, lo que indica que el factor autoritarismo está bien medido por estos ítems.
dominancia =~:dom1: Carga no estandarizada fijada a 1.000. Carga estandarizada (Std.all) = 0.919.dom2: Carga estandarizada (Std.all) = 0.882; significativa (p < 0.001).dom3: Carga estandarizada (Std.all) = 0.685; significativa (p < 0.001).dom1ydom2tienen cargas altas y homogéneas.dom3muestra una carga más baja (0.685), lo que es aceptable pero señala que este ítem captura algo más que el núcleo del factor dominancia — un patrón que la evaluación local confirmará.
Covariances:autoritarismo ~~ dominancia: La covarianza estimada es 0.678. La correlación estandarizada (Std.all) entre los dos factores latentes es 0.343. Esta correlación es positiva, moderada y estadísticamente significativa (P(>|z|) = 0.000), indicando que “autoritarismo” y “dominancia social” son constructos relacionados pero distintos.
Variances: Muestra las varianzas de los errores de los indicadores (ej..aut1= 0.582) y las varianzas estimadas de los factores latentes (autoritarismo= 2.711,dominancia= 1.442 en la escala no estandarizada).R-Square(Comunalidades):aut1: 0.823 (82.3% de su varianza es explicada por el factor “autoritarismo”)aut2: 0.787 (78.7%)aut3: 0.644 (64.4%)dom1: 0.845 (84.5% de su varianza es explicada por el factor “dominancia”)dom2: 0.778 (77.8%)dom3: 0.469 (46.9%)- Todas las comunalidades son de moderadas a altas, indicando que los factores explican una buena proporción de la varianza de sus respectivos indicadores.
dom3es el que tiene la comunalidad más baja (46.9%), lo que significa que casi la mitad de su varianza no es explicada por el factor “dominancia”.
Índices de Ajuste Específicos
Podemos solicitar un conjunto específico de índices de ajuste.
# Ver solo los índices de ajuste seleccionados
fitMeasures(mod_conf_afc,
fit.measures = c("chisq", "df", "pvalue", # Prueba Chi-cuadrado
"cfi", "tli", # Índices Comparativos
"rmsea", "rmsea.ci.lower", "rmsea.ci.upper", # RMSEA y su IC 90%
"srmr")) # Standardized Root Mean Square Residual chisq df pvalue cfi tli
12.332 8.000 0.137 0.993 0.987
rmsea rmsea.ci.lower rmsea.ci.upper srmr
0.055 0.000 0.113 0.049 Interpretación de los Índices de Ajuste Global:
Nota metodológica: Los umbrales que se usan a continuación (RMSEA < 0.05, CFI > 0.95) son heurísticos aproximados, derivados de simulaciones específicas (Hu & Bentler, 1999). No son leyes universales: su interpretación depende del tamaño de muestra, número de indicadores y complejidad del modelo. Siempre deben complementarse con la evaluación del ajuste local (ver sección siguiente).
chisq= 12.332,df= 8,pvalue= 0.137:- El p-valor (0.137) es mayor que 0.05, por lo que no rechazamos la hipótesis nula de buen ajuste. Este es un indicador favorable.
- \(\chi^2/gl = 12.332 / 8 \approx 1.54\). Este valor por debajo de 2 sugiere un ajuste razonable según este criterio.
cfi= 0.993: Valor cercano a 1 (y > 0.95), sugiere un buen ajuste comparativo. Recuerda que este índice puede verse inflado con muestras pequeñas.tli= 0.987: También cercano a 1 (y > 0.95), sugiere un buen ajuste comparativo.rmsea= 0.055:- Este valor está en el límite entre “buen ajuste” (\(\leq 0.05\)) y “ajuste razonable” (0.05-0.08). No es un resultado inequívocamente positivo.
- IC 90% para RMSEA: 0.000 - 0.113. El intervalo es amplio e incluye valores por encima de 0.10, lo que introduce incertidumbre sobre la precisión de esta estimación.
srmr= 0.049: Por debajo de 0.08, sugiere un ajuste aceptable en términos de residuos estandarizados promedio.
Evaluación preliminar del ajuste global: Los índices globales son, en conjunto, favorables. Sin embargo, recuerda que un buen ajuste global no garantiza que el modelo esté correctamente especificado en todos sus detalles. La siguiente sección examina el ajuste a nivel local.
4.2 Evaluación del Ajuste Local (Matriz de Residuos de Correlación)
El ajuste global resume el modelo en un único número y puede esconder discrepancias locales importantes. La matriz de residuos de correlación muestra las diferencias entre las correlaciones observadas en los datos y las correlaciones que el modelo implica para cada par de ítems. El umbral de referencia para detectar problemas es un residuo con valor absoluto > 0.10.
Un punto importante sobre por qué se usa ese umbral y no los residuos estandarizados: los residuos estandarizados dependen del tamaño de muestra y con N grandes (ej. N > 1.000) casi cualquier residuo pequeño resulta “estadísticamente significativo”. El umbral de 0.10 sobre la escala de correlaciones evalúa el tamaño del efecto del desajuste, independientemente de N — lo que nos interesa para juzgar si el modelo capta bien la realidad (Kline, 2023).
# Calcular y extraer directamente la matriz de residuos de correlación
residuos_cor <- lavResiduals(mod_conf_afc, type = "cor")$cov
print(residuos_cor) aut1 aut2 aut3 dom1 dom2 dom3
aut1 0.000
aut2 -0.001 0.000
aut3 -0.001 0.003 0.000
dom1 0.020 0.012 -0.014 0.000
dom2 0.028 0.015 0.018 -0.002 0.000
dom3 -0.075 -0.149 -0.142 0.004 0.005 0.000Interpretación de los residuos:
La matriz muestra el siguiente patrón:
- Ítems dentro del mismo factor (
aut1-aut2-aut3entre sí, ydom1-dom2entre sí): todos los residuos son prácticamente cero (entre -0.001 y 0.003), lo que indica que el modelo reproduce con precisión las correlaciones dentro de cada factor. dom3con los ítems deautoritarismo: aquí aparece el problema.dom3~aut2: residuo = -0.149 → supera el umbral de 0.10.dom3~aut3: residuo = -0.142 → supera el umbral de 0.10.dom3~aut1: residuo = -0.075 → por debajo del umbral, pero no despreciable.
Un residuo negativo significa que la correlación observada entre esos dos ítems es menor que la que el modelo predice. El modelo, al conectar dom3 con autoritarismo a través de la correlación inter-factor (r = 0.343), sobreestima la relación real de dom3 con los ítems de autoritarismo.
Evaluación local: el ajuste local no es satisfactorio para los pares que involucran a dom3 con los ítems de autoritarismo. Este es exactamente el tipo de problema que el CFI = 0.993 esconde: el modelo ajusta bien en promedio, pero dom3 se comporta de forma algo atípica respecto a los demás ítems de su factor. Este hallazgo es consistente con su comunalidad más baja (R² = 0.469) y tendrá implicancias directas para la lectura de los índices de modificación.
5. Visualización del Modelo (usando semPlot)
semPaths puede graficar el modelo, mostrando las cargas estandarizadas.
# Diagrama del modelo con cargas estandarizadas
semPlot::semPaths(mod_conf_afc,
what = "std", # Mostrar cargas estandarizadas (Std.all)
whatLabels = "std",
residuals = TRUE,
intercepts = FALSE,
edge.color = "black"
) # Márgenes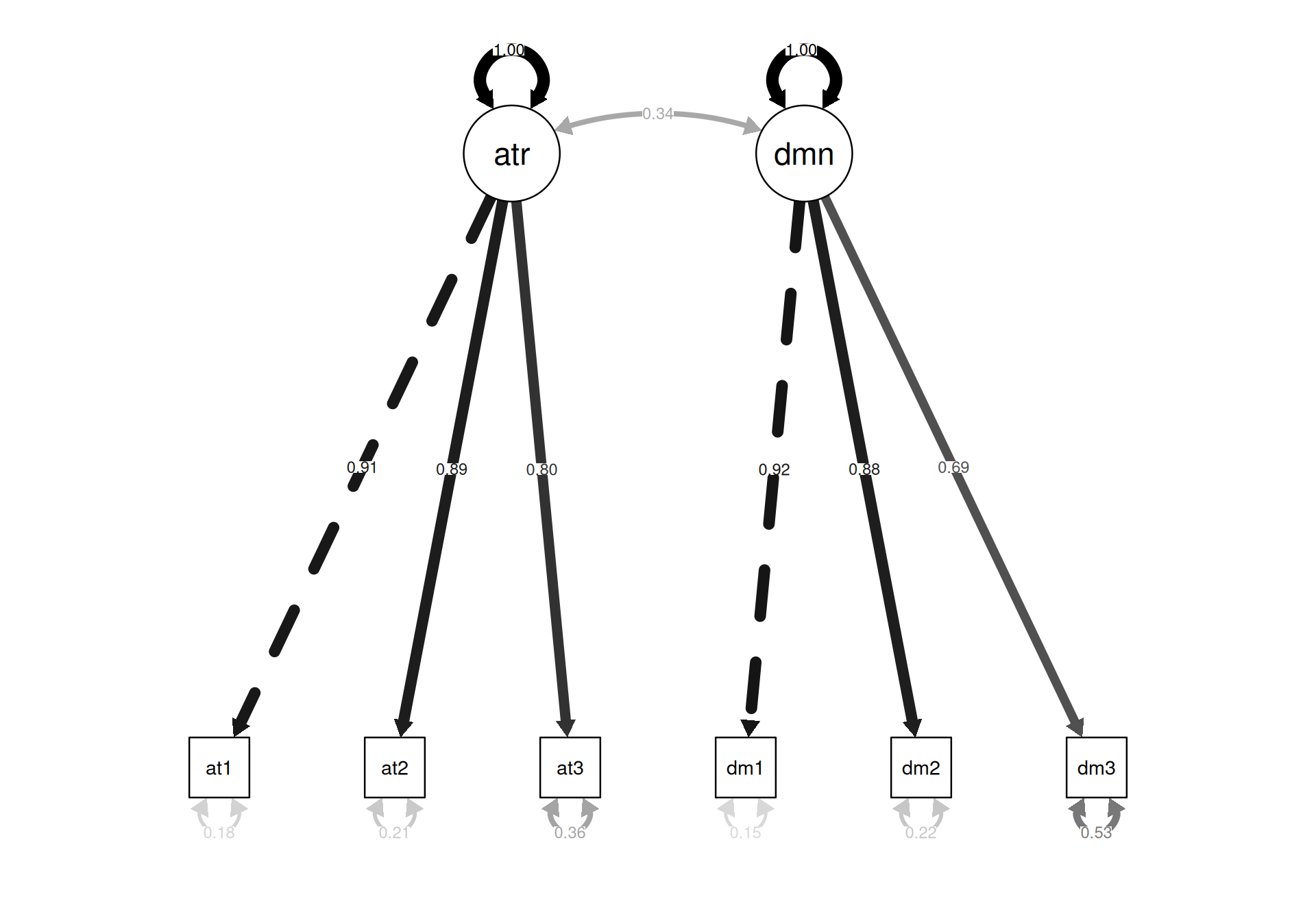
Interpretación del Gráfico: El diagrama visualiza el modelo teórico. Las flechas desde los óvalos (factores latentes autoritarismo y dominancia) a los rectángulos (ítems aut1-3 y dom1-3) muestran las cargas factoriales estandarizadas (Std.all). La línea curva entre autoritarismo y dominancia representa su correlación (0.343). Las pequeñas flechas hacia cada ítem indican sus varianzas de error (1 - R²). Este gráfico confirma visualmente que todos los ítems cargan sustancialmente en sus factores designados y que los factores están moderadamente correlacionados.
6. Comunalidades (R-cuadrado de los Indicadores)
Las comunalidades indican qué proporción de la varianza de cada ítem es explicada por el factor latente en el que carga.
# Obtener R-cuadrado (comunalidades) para las variables observadas
inspect(mod_conf_afc, what = "rsquare") aut1 aut2 aut3 dom1 dom2 dom3
0.823 0.787 0.644 0.845 0.778 0.469 Interpretación:
- aut1: 0.823 (El factor
autoritarismoexplica el 82.3% de la varianza deaut1). - aut2: 0.787 (78.7%)
- aut3: 0.644 (64.4%)
- dom1: 0.845 (El factor
dominanciaexplica el 84.5% de la varianza dedom1). - dom2: 0.778 (77.8%)
- dom3: 0.469 (46.9%) Todas las comunalidades son buenas (mayores a 0.40, y la mayoría > 0.60). El ítem
dom3es el que tiene la comunalidad más baja (46.9%), lo que significa que más de la mitad de su varianza es única o error. Sin embargo, dado que su carga factorial (0.685) sigue siendo aceptable, y el modelo general ajusta bien, podría mantenerse.
7. Índices de Modificación (Para Explorar Mejoras)
Los índices de modificación (IM) señalan qué cambios al modelo reducirían significativamente el estadístico χ². Son una herramienta exploratoria útil, pero deben usarse con máxima cautela.
# Mostrar los IM más altos, ordenados (IM > 3.84 es aprox. p<0.05 con 1gl)
mod_indices <- modificationindices(mod_conf_afc, sort. = TRUE, minimum.value = 3.84)
print(head(mod_indices, 10)) lhs op rhs mi epc sepc.lv sepc.all sepc.nox
18 autoritarismo =~ dom3 6.437 -0.152 -0.250 -0.165 -0.165
34 dom1 ~~ dom2 6.437 -0.982 -0.982 -2.719 -2.719
30 aut2 ~~ dom3 4.180 -0.170 -0.170 -0.196 -0.196Interpretación de los IM:
Aparecen tres cambios que superan el umbral de 3.84:
autoritarismo =~ dom3(mi= 6.437,epc= -0.152): el modelo sugiere añadirdom3como indicador del factor autoritarismo con una carga negativa. Esto es coherente con los residuos: el modelo sobreestima cuánto se relacionadom3con los ítems de autoritarismo, y liberar una carga negativa compensaría esa sobreestimación.dom1 ~~ dom2(mi= 6.437,epc= -0.982): correlacionar los errores dedom1ydom2. Ambos comparten una redacción que apela al “lugar” de los grupos (“quedarse en su lugar” / “mantenerse en su lugar”), lo que podría justificar teóricamente esta correlación.aut2 ~~ dom3(mi= 4.180,epc= -0.170): correlacionar los errores deaut2ydom3, también coherente con los residuos negativos identificados en la sección anterior.
Nota que los tres IM involucran a dom3, el mismo ítem que ya mostraba residuos locales problemáticos. Esto no es coincidencia: los MIs y los residuos son dos formas distintas de detectar el mismo problema de especificación.
Capitalización del azar y HARKing
Que los MIs sean consistentes con los residuos no los convierte automáticamente en modificaciones justificadas. Aplicarlos mecánicamente — porque el valor supera 3.84 — es un ejemplo de capitalización del azar: se ajusta el modelo a las particularidades de esta muestra, no a la teoría. Esta práctica se conoce como HARKing (Hypothesizing After the Results are Known) y convierte el AFC en un análisis exploratorio sin que quede explícito en el reporte. Correlacionar los errores de
dom1ydom2tiene una justificación teórica plausible (redacción casi idéntica), pero eso debe haber sido identificado antes de mirar el IM — no después. Liberaraut2 ~~ dom3requiere una explicación de por qué esos dos ítems en particular comparten varianza más allá de sus factores, y esa explicación no es obvia a partir del contenido.
Si decides reespecificar el modelo guiándote por los IM:
- Documenta la justificación teórica antes de hacer el cambio.
- Reporta el modelo reespecificado como exploratorio, no confirmatorio.
- Valida el modelo modificado en una muestra independiente antes de presentarlo como resultado definitivo.
Decisión en este caso: Los residuos locales confirman un problema real con dom3. Sin embargo, los MIs no ofrecen una solución teóricamente limpia: la carga cruzada negativa en autoritarismo no tiene interpretación sustantiva clara, y la correlación de errores con aut2 tampoco. La opción más defendible es mantener el modelo de dos factores original, reportando la limitación de dom3 (comunalidad 0.469, residuos locales elevados con los ítems de autoritarismo) y evaluando en trabajos futuros si este ítem debería ser revisado o eliminado del instrumento.
8. Conclusión
En este práctico, hemos:
- Especificado y estimado un modelo AFC de dos factores con
lavaan(N = 176, estimador ML). - Evaluado el ajuste global: χ²(8) = 12.332 (p = 0.137), CFI = 0.993, TLI = 0.987, RMSEA = 0.055 [0.000, 0.113], SRMR = 0.049. Los índices globales son favorables, aunque el intervalo del RMSEA es amplio. Estos valores son heurísticos, no criterios absolutos.
- Evaluado el ajuste local: la matriz de residuos de correlación reveló que la mayoría de los pares de ítems tienen residuos cercanos a cero, pero
dom3presenta residuos que superan el umbral de 0.10 conaut2(−0.149) yaut3(−0.142). El modelo sobreestima la relación dedom3con el factor autoritarismo — un problema que el CFI global escondía. - Interpretado las cargas factoriales: todas son positivas, significativas, y superiores a 0.68. Los factores están moderadamente correlacionados (r = 0.343).
- Examinado las comunalidades: cinco de los seis ítems superan 0.64;
dom3es el más débil (R² = 0.469), coherente con todos los indicadores anteriores. - Analizado los índices de modificación críticamente: los tres cambios sugeridos involucran a
dom3, confirmando que es el ítem problemático. Ninguna modificación tiene una justificación teórica suficientemente sólida para alterar el modelo.
El modelo de dos factores correlacionados es la especificación más parsimoniosamente defendible para estos datos. La limitación principal es dom3, cuyo comportamiento atípico respecto al factor autoritarismo es una señal para revisar el instrumento en estudios futuros.
Reflexión final — Modelos Equivalentes:
El hecho de que este modelo de dos factores correlacionados ajuste bien a los datos no demuestra que sea el único modelo verdadero, ni siquiera que sea el mejor. Estadísticamente, existen modelos equivalentes: especificaciones alternativas (con diferente número de factores, diferentes restricciones, o incluso modelos causales distintos) que reproducirían exactamente la misma matriz de covarianza y, por tanto, tendrían idénticos valores de CFI, RMSEA y χ². El buen ajuste es evidencia consistente con la teoría, no prueba de ella. La selección del modelo correcto siempre depende en última instancia del argumento teórico sustantivo.