
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
tidyverse,
psych,
GPArotation,
survey
)Práctico 7: Análisis Factorial Exploratorio II
Extracción, Rotación e Interpretación
0. Objetivos del Práctico
Continuamos directamente desde el Práctico 6. Los objetivos de esta sesión son:
- Determinar el número de factores a retener (Scree Plot y Análisis Paralelo).
- Ejecutar el AFE con correlaciones policóricas, método
minresy ponderación muestral. - Comparar rotaciones ortogonal (Varimax) y oblicua (Promax).
- Interpretar la matriz de cargas e identificar y nombrar los factores.
- Visualizar la estructura con
fa.diagram(). - Calcular puntuaciones factoriales y explorar diferencias por grupos con pruebas de significación.
1. Carga y Preparación de Datos
Replicamos los pasos de limpieza del Práctico 6, agregando el factor de expansión (fact_exp02) y las variables de diseño muestral (estrato, segmento).
# Carga el archivo desde la carpeta raíz de tu proyecto
load("ELSOC_Long_2016_2023.RData")datos <- elsoc_long_2016_2023 %>%
filter(ola == 7) %>%
select(
idencuesta,
arraigo1 = t02_01,
arraigo2 = t02_02,
arraigo3 = t02_03,
arraigo4 = t02_04,
cohesion1 = t03_01,
cohesion2 = t03_02,
cohesion3 = t03_03,
cohesion4 = t03_04,
sexo = m0_sexo,
edad = m0_edad,
educ = m01,
region = region_cod,
peso = fact_exp02, # Factor de expansión corte transversal
estrato,
segmento
) %>%
mutate(across(starts_with(c("arraigo", "cohesion")),
~ ifelse(.x %in% c(-777, -888, -999), NA, .x)))
# Listwise sobre los 8 ítems del AFE
datos_completos <- datos %>%
drop_na(starts_with(c("arraigo", "cohesion")))
# Mahalanobis
vars_afe <- datos_completos %>% select(starts_with(c("arraigo", "cohesion")))
n_vars <- ncol(vars_afe)
D2 <- mahalanobis(vars_afe, colMeans(vars_afe), cov(vars_afe))
datos_completos$p_mah <- 1 - pchisq(D2, df = n_vars)
datos_completos <- datos_completos %>% filter(p_mah > 0.001) %>% select(-p_mah)
# Base solo con ítems para el AFE
datosLW <- datos_completos %>% select(starts_with(c("arraigo", "cohesion")))
# Vector de pesos alineado con datosLW
pesos <- datos_completos$peso
nrow(datosLW)[1] 26112. Determinando el Número de Factores
Gráfico de Sedimentación (Scree Plot)
scree(datosLW, factors = TRUE, pc = TRUE,
main = "Scree Plot — Arraigo e Integración Barrial (ELSOC 2023)")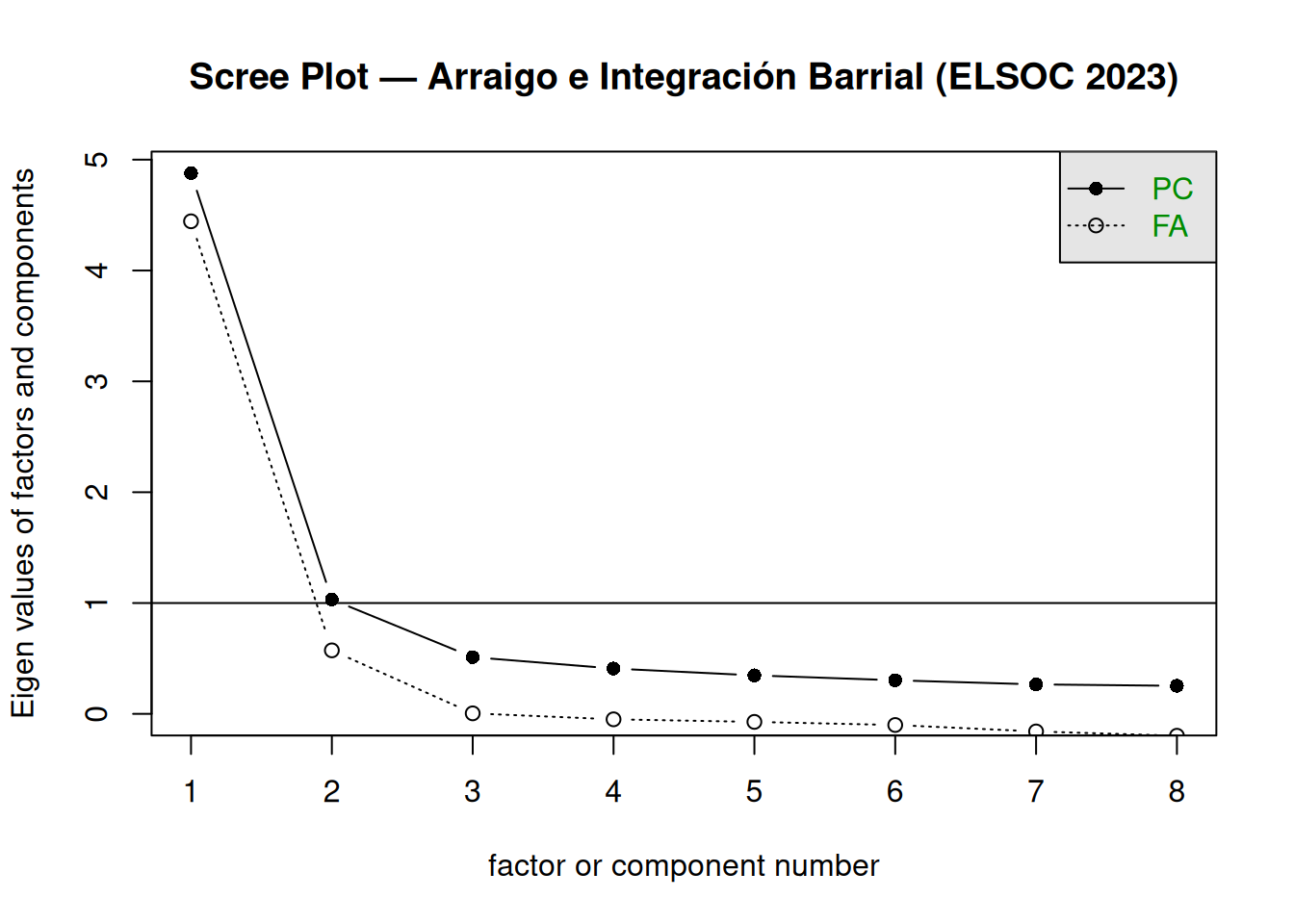
Interpretación: El primer autovalor FA es notablemente más alto que los siguientes. El segundo todavía se encuentra claramente por encima del tercero, que ya entra en la zona plana de la curva. El criterio del codo apunta con claridad a 2 factores, coherente con la distinción teórica entre arraigo personal y cohesión barrial percibida. El criterio de Kaiser (autovalor FA > 0) también sugiere 2 factores en este caso.
Análisis Paralelo
set.seed(2023)
fa.parallel(datosLW, fa = "fa",
main = "Análisis Paralelo — Arraigo e Integración Barrial")
Parallel analysis suggests that the number of factors = 2 and the number of components = NA Interpretación: El output indica explícitamente Parallel analysis suggests that the number of factors = 2. Los dos primeros autovalores de los datos reales superan los generados por datos aleatorios del mismo tamaño; a partir del tercero caen por debajo del umbral de azar. Scree Plot y Análisis Paralelo coinciden en retener 2 factores.
3. Análisis Factorial Exploratorio con 2 Factores
Solución Sin Rotar
fa(datosLW, nfactors = 2, fm = "minres", rotate = "none", cor = "poly",
weight = pesos)Factor Analysis using method = minres
Call: fa(r = datosLW, nfactors = 2, rotate = "none", fm = "minres",
cor = "poly", weight = pesos)
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR2 h2 u2 com
arraigo1 0.73 -0.37 0.67 0.33 1.5
arraigo2 0.86 -0.28 0.82 0.18 1.2
arraigo3 0.86 -0.22 0.79 0.21 1.1
arraigo4 0.81 -0.32 0.76 0.24 1.3
cohesion1 0.74 0.26 0.61 0.39 1.2
cohesion2 0.79 0.45 0.82 0.18 1.6
cohesion3 0.81 0.29 0.74 0.26 1.2
cohesion4 0.70 0.26 0.56 0.44 1.3
MR1 MR2
SS loadings 4.99 0.79
Proportion Var 0.62 0.10
Cumulative Var 0.62 0.72
Proportion Explained 0.86 0.14
Cumulative Proportion 0.86 1.00
Mean item complexity = 1.3
Test of the hypothesis that 2 factors are sufficient.
df null model = 28 with the objective function = 6.26 with Chi Square = 16307.23
df of the model are 13 and the objective function was 0.12
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 2611 with the empirical chi square 25.65 with prob < 0.019
The total n.obs was 2611 with Likelihood Chi Square = 311.3 with prob < 1e-58
Tucker Lewis Index of factoring reliability = 0.961
RMSEA index = 0.094 and the 90 % confidence intervals are 0.085 0.103
BIC = 209.02
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.98 0.88
Multiple R square of scores with factors 0.95 0.77
Minimum correlation of possible factor scores 0.91 0.53Interpretación: MR1 actúa como factor general con cargas altas en todos los ítems (rango 0.70–0.86), explicando el 62% de la varianza. MR2 contrasta los dos bloques: cargas negativas en los ítems de arraigo (–0.22 a –0.37) y positivas en los de cohesión (0.26–0.45). Juntos explican el 72% de la varianza. Esta estructura “general + contraste” es característica antes de la rotación y dificulta la interpretación sustantiva de los factores. La rotación es necesaria.
Rotación Ortogonal (Varimax)
fa(datosLW, nfactors = 2, fm = "minres", rotate = "varimax", cor = "poly",
weight = pesos)Factor Analysis using method = minres
Call: fa(r = datosLW, nfactors = 2, rotate = "varimax", fm = "minres",
cor = "poly", weight = pesos)
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR2 h2 u2 com
arraigo1 0.78 0.24 0.67 0.33 1.2
arraigo2 0.81 0.39 0.82 0.18 1.4
arraigo3 0.78 0.44 0.79 0.21 1.6
arraigo4 0.81 0.33 0.76 0.24 1.3
cohesion1 0.35 0.70 0.61 0.39 1.5
cohesion2 0.26 0.87 0.82 0.18 1.2
cohesion3 0.39 0.77 0.74 0.26 1.5
cohesion4 0.33 0.68 0.56 0.44 1.4
MR1 MR2
SS loadings 2.98 2.80
Proportion Var 0.37 0.35
Cumulative Var 0.37 0.72
Proportion Explained 0.52 0.48
Cumulative Proportion 0.52 1.00
Mean item complexity = 1.4
Test of the hypothesis that 2 factors are sufficient.
df null model = 28 with the objective function = 6.26 with Chi Square = 16307.23
df of the model are 13 and the objective function was 0.12
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 2611 with the empirical chi square 25.65 with prob < 0.019
The total n.obs was 2611 with Likelihood Chi Square = 311.3 with prob < 1e-58
Tucker Lewis Index of factoring reliability = 0.961
RMSEA index = 0.094 and the 90 % confidence intervals are 0.085 0.103
BIC = 209.02
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.93 0.92
Multiple R square of scores with factors 0.87 0.85
Minimum correlation of possible factor scores 0.74 0.70Interpretación: Varimax clarifica la estructura: MR1 agrupa los ítems de arraigo (cargas 0.78–0.81) y MR2 los de cohesión (cargas 0.68–0.87, con la carga más alta en cohesion2=0.87). Sin embargo, persisten cargas cruzadas notables: arraigo3 carga 0.44 en MR2, arraigo2 carga 0.39, y los ítems de cohesión cargan entre 0.26 y 0.39 en MR1. La complejidad media de los ítems es 1.4, indicando que en promedio cada ítem carga en más de un factor. Esto sugiere que los factores están relacionados y que el supuesto de ortogonalidad de Varimax no es adecuado para estos datos.
Rotación Oblicua (Promax) — Modelo Final
modelofinal <- fa(datosLW, nfactors = 2, fm = "minres", rotate = "promax",
cor = "poly", weight = pesos)
modelofinalFactor Analysis using method = minres
Call: fa(r = datosLW, nfactors = 2, rotate = "promax", fm = "minres",
cor = "poly", weight = pesos)
Standardized loadings (pattern matrix) based upon correlation matrix
MR1 MR2 h2 u2 com
arraigo1 0.88 -0.10 0.67 0.33 1.0
arraigo2 0.84 0.09 0.82 0.18 1.0
arraigo3 0.77 0.16 0.79 0.21 1.1
arraigo4 0.87 0.01 0.76 0.24 1.0
cohesion1 0.09 0.72 0.61 0.39 1.0
cohesion2 -0.13 0.99 0.82 0.18 1.0
cohesion3 0.10 0.79 0.74 0.26 1.0
cohesion4 0.07 0.70 0.56 0.44 1.0
MR1 MR2
SS loadings 2.99 2.79
Proportion Var 0.37 0.35
Cumulative Var 0.37 0.72
Proportion Explained 0.52 0.48
Cumulative Proportion 0.52 1.00
With factor correlations of
MR1 MR2
MR1 1.00 0.69
MR2 0.69 1.00
Mean item complexity = 1
Test of the hypothesis that 2 factors are sufficient.
df null model = 28 with the objective function = 6.26 with Chi Square = 16307.23
df of the model are 13 and the objective function was 0.12
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 2611 with the empirical chi square 25.65 with prob < 0.019
The total n.obs was 2611 with Likelihood Chi Square = 311.3 with prob < 1e-58
Tucker Lewis Index of factoring reliability = 0.961
RMSEA index = 0.094 and the 90 % confidence intervals are 0.085 0.103
BIC = 209.02
Fit based upon off diagonal values = 1
Measures of factor score adequacy
MR1 MR2
Correlation of (regression) scores with factors 0.89 0.95
Multiple R square of scores with factors 0.79 0.90
Minimum correlation of possible factor scores 0.58 0.81Interpretación (Matriz de Patrón):
- MR1 agrupa
arraigo1–arraigo4con cargas entre 0.77 y 0.88, y cargas cruzadas negligibles (–0.10 a 0.16). Captura el arraigo barrial: la identificación personal con el barrio como parte de la propia identidad. - MR2 agrupa
cohesion1–cohesion4con cargas entre 0.70 y 0.99, y cargas cruzadas también negligibles (–0.13 a 0.16). Captura la cohesión barrial percibida: la evaluación de la sociabilidad, cordialidad y disposición colaborativa de los vecinos. La carga decohesion2(“La gente es sociable”) es 0.99, indicando que es el ítem más representativo de esta dimensión. - La complejidad media = 1.0 confirma estructura simple perfecta: cada ítem carga prácticamente en un solo factor.
- La correlación entre factores = 0.69 (alta) retroactivamente valida la elección de la rotación oblicua: los factores están sustancialmente relacionados, lo que habría sesgado los resultados de Varimax al forzar ortogonalidad.
- Los dos factores explican en conjunto el 72% de la varianza (MR1=37%, MR2=35%), con una distribución prácticamente simétrica entre dimensiones.
Índices de ajuste:
| Índice | Valor obtenido | Criterio |
|---|---|---|
| TLI | 0.961 | > 0.95: muy bueno |
| RMSEA | 0.094 (IC90%: 0.085–0.103) | > 0.08: ajuste marginal |
| RMSR | 0.02 | < 0.05: muy bueno |
El TLI=0.961 y el RMSR=0.02 indican buen ajuste. El RMSEA=0.094 supera el umbral de 0.08, señalando un ajuste marginal del modelo de 2 factores a los datos. En parte esto puede deberse al gran tamaño muestral (n=2,611), que hace muy sensibles las pruebas basadas en chi-cuadrado. El RMSR bajo (0.02) indica que los residuos de la matriz de correlaciones son pequeños, lo que es más informativo con muestras grandes.
Nota sobre la ponderación: El argumento weight en psych::fa() incorpora los pesos de expansión en el cálculo, haciendo que la solución factorial refleje la población objetivo. Sin embargo, no equivale a un análisis de diseño muestral complejo completo: no incorpora estratificación ni conglomerados en el cálculo de errores estándar, por lo que las pruebas de ajuste (chi-cuadrado, RMSEA) deben interpretarse con cautela adicional.
4. Visualización de la Estructura Factorial
fa.diagram(modelofinal,
main = "Estructura Factorial: Arraigo e Integración Barrial (ELSOC 2023)")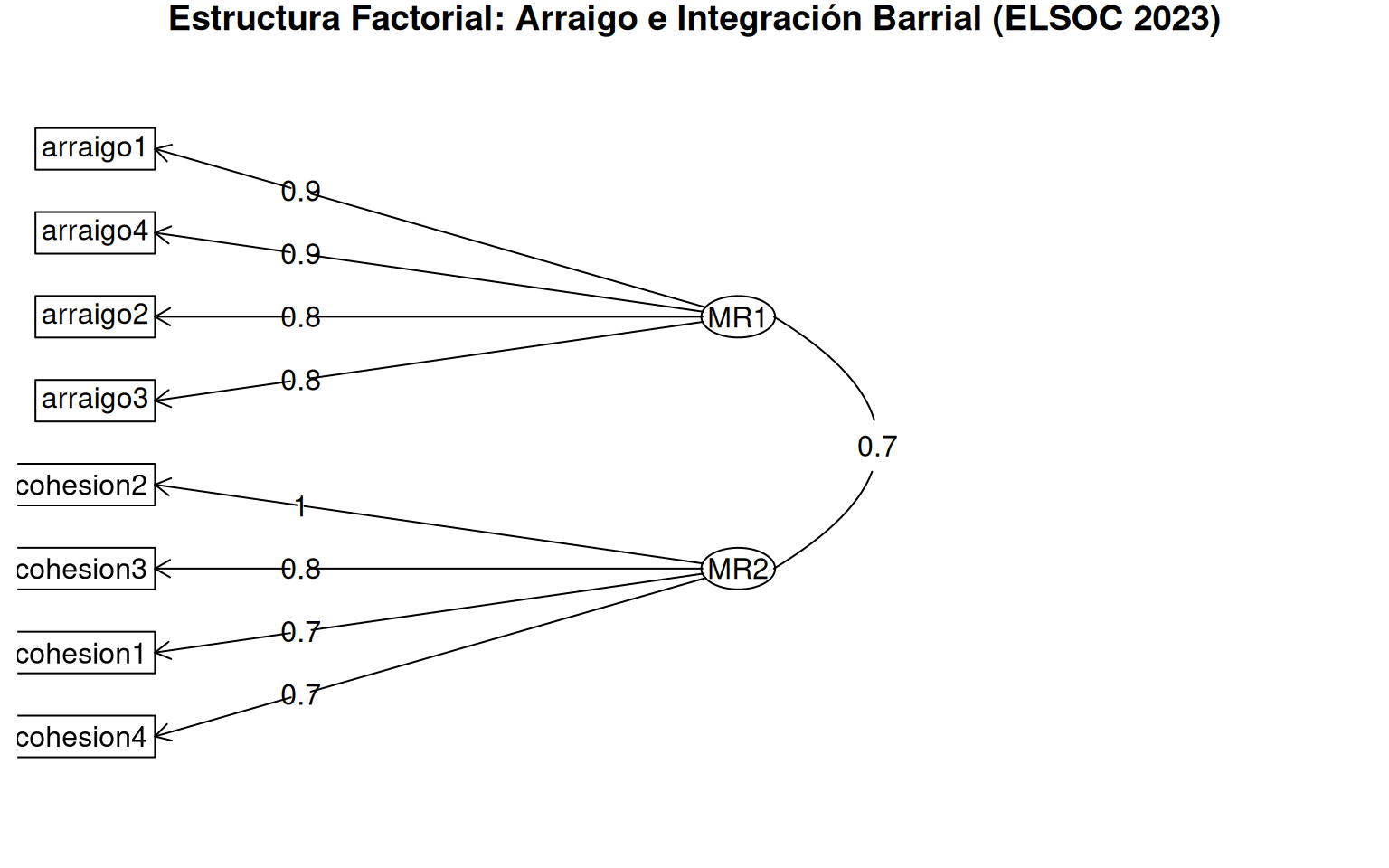
Interpretación: Los rectángulos representan ítems observados; los óvalos, los factores latentes. Las flechas muestran las cargas de la matriz de patrón (grosor proporcional a la magnitud). La línea curva entre los óvalos representa la correlación entre factores (0.69). El diagrama confirma la estructura simple: las cuatro flechas de mayor grosor del factor de arraigo apuntan exclusivamente a arraigo1–arraigo4, y las del factor de cohesión a cohesion1–cohesion4, sin flechas cruzadas de magnitud visible.
5. Puntuaciones Factoriales y Diferencias por Grupos
puntuaciones <- factor.scores(datosLW, modelofinal, method = "Thurstone")
summary(puntuaciones$scores) MR1 MR2
Min. :-3.6173 Min. :-3.5226
1st Qu.:-0.4625 1st Qu.:-0.5554
Median : 0.3131 Median : 0.2425
Mean : 0.0000 Mean : 0.0000
3rd Qu.: 0.3912 3rd Qu.: 0.5100
Max. : 1.7764 Max. : 1.8851 datos_analisis <- datos_completos %>%
select(idencuesta, sexo, edad, educ, region, peso, estrato, segmento) %>%
bind_cols(as.data.frame(puntuaciones$scores) %>%
rename(arraigo = MR1, cohesion = MR2)) %>%
mutate(
sexo_label = factor(sexo, levels = 1:2, labels = c("Hombre", "Mujer")),
educ_grupo = case_when(
educ %in% 1:3 ~ "1. Básica o menos",
educ %in% 4:6 ~ "2. Media",
educ %in% 7:10 ~ "3. Superior",
TRUE ~ NA_character_
) |> factor()
)Diferencias por Sexo
datos_analisis %>%
filter(!is.na(sexo_label)) %>%
group_by(sexo_label) %>%
summarise(
n = n(),
arraigo_media = round(mean(arraigo, na.rm = TRUE), 3),
cohesion_media = round(mean(cohesion, na.rm = TRUE), 3)
)t.test(arraigo ~ sexo_label, data = datos_analisis)
Welch Two Sample t-test
data: arraigo by sexo_label
t = 3.0535, df = 2016.7, p-value = 0.002292
alternative hypothesis: true difference in means between group Hombre and group Mujer is not equal to 0
95 percent confidence interval:
0.04392118 0.20162853
sample estimates:
mean in group Hombre mean in group Mujer
0.07847998 -0.04429487 t.test(cohesion ~ sexo_label, data = datos_analisis)
Welch Two Sample t-test
data: cohesion by sexo_label
t = 2.5475, df = 1982.9, p-value = 0.01093
alternative hypothesis: true difference in means between group Hombre and group Mujer is not equal to 0
95 percent confidence interval:
0.02352209 0.18088252
sample estimates:
mean in group Hombre mean in group Mujer
0.06532962 -0.03687268 Interpretación: Los hombres presentan puntuaciones más altas que las mujeres tanto en arraigo (0.078 vs. –0.044, diferencia de 0.12 DE) como en cohesión (0.065 vs. –0.037, diferencia de 0.10 DE). Ambas diferencias son estadísticamente significativas (arraigo: t=3.05, p=0.002; cohesión: t=2.55, p=0.011). Las magnitudes son pequeñas pero consistentes en las dos dimensiones, lo que sugiere que los hombres evalúan su entorno barrial de forma algo más favorable que las mujeres en ambas dimensiones. Este resultado es contrario a la hipótesis de que las mujeres, al pasar más tiempo en el barrio, reportarían mayor arraigo.
Diferencias por Nivel Educativo
datos_analisis %>%
filter(!is.na(educ_grupo)) %>%
group_by(educ_grupo) %>%
summarise(
n = n(),
arraigo_media = round(mean(arraigo, na.rm = TRUE), 3),
cohesion_media = round(mean(cohesion, na.rm = TRUE), 3)
)summary(aov(arraigo ~ educ_grupo, data = datos_analisis)) Df Sum Sq Mean Sq F value Pr(>F)
educ_grupo 2 0.8 0.3775 0.378 0.685
Residuals 2608 2604.3 0.9986 summary(aov(cohesion ~ educ_grupo, data = datos_analisis)) Df Sum Sq Mean Sq F value Pr(>F)
educ_grupo 2 2 0.9902 1.009 0.365
Residuals 2608 2560 0.9814 Interpretación: Las diferencias por nivel educativo son mínimas y estadísticamente no significativas: F=0.38 (p=0.685) para arraigo y F=1.01 (p=0.365) para cohesión. Las medias de los tres grupos están muy próximas entre sí (rango de apenas 0.045 DE para arraigo y 0.074 DE para cohesión). La hipótesis de que el arraigo sería mayor entre quienes tienen menor nivel educativo —por menor movilidad residencial— no se confirma en estos datos de ELSOC 2023: las puntuaciones factoriales no varían de forma apreciable según el nivel de estudios.
6. Diseño Muestral Complejo: Opciones en R
Los análisis anteriores incorporan los pesos de expansión (fact_exp02) mediante el argumento weight de psych::fa(). Esto hace que la solución factorial refleje la población objetivo. Sin embargo, ELSOC emplea un diseño estratificado por conglomerados, donde la inferencia correcta requiere también incorporar los estratos (estrato) y segmentos (segmento) en el cálculo de varianzas. Existen dos alternativas en R con distintos alcances:
Opción 1 — psych::fa() con pesos (lo que hicimos)
Incorpora pesos por observación para que la solución factorial sea representativa de la población. No modifica el cálculo de errores estándar ni los índices de ajuste, que siguen asumiendo muestreo aleatorio simple. Es una solución razonable para exploración y docencia.
Opción 2 — survey::svyfactanal() con diseño complejo
Estima la matriz de covarianzas bajo diseño complejo usando svyvar() y luego aplica factanal(). Esta función incorpora estratificación y conglomerados tanto en la estimación como en la inferencia. Su limitación es que se basa en factanal() (máxima verosimilitud, sin la flexibilidad de psych), y su propia documentación la marca como experimental.
# Definir el diseño muestral complejo de ELSOC
disenio <- svydesign(
ids = ~segmento,
strata = ~estrato,
weights = ~peso,
data = datos_completos,
nest = TRUE
)
# AFE con diseño complejo (máxima verosimilitud, 2 factores)
svyfactanal(
~arraigo1 + arraigo2 + arraigo3 + arraigo4 +
cohesion1 + cohesion2 + cohesion3 + cohesion4,
design = disenio,
factors = 2,
n = "effective" # Usa el N efectivo para los tests de ajuste
)En síntesis:
| Enfoque | Representatividad | Inferencia bajo diseño complejo | Flexibilidad |
|---|---|---|---|
psych::fa(weight=...) |
Sí | No | Alta (minres, promax, policórica) |
survey::svyfactanal() |
Sí | Sí (experimental) | Baja (solo ML) |
Para un paper o reporte donde el diseño de encuesta importa para la inferencia, la solución con pesos en psych no reemplaza un análisis design-based completo. En ese caso, se puede usar svyfactanal() para las pruebas de ajuste y psych para la exploración de la estructura.
7. Conclusión
- 2 factores retenidos (Scree Plot y Análisis Paralelo coinciden con la estructura teórica).
- Extracción con correlaciones policóricas,
fm = "minres"y pesos de expansión (fact_exp02). - La rotación Promax fue preferida sobre Varimax por la correlación moderada entre factores.
- Los factores identificados — arraigo barrial (t02) y cohesión barrial percibida (t03) — corresponden a las dimensiones teóricamente propuestas.
- Las comparaciones por sexo y nivel educativo, con sus pruebas de significación, permiten explorar si las puntuaciones varían sistemáticamente entre grupos. La interpretación causal requiere cautela dado el diseño observacional.
- Para inferencias poblacionales rigurosas con ELSOC, el diseño muestral complejo (estratos y segmentos) debe incorporarse, ya sea con
psych::fa(weight=...)para la estructura o consurvey::svyfactanal()para inferencia design-based.