
library(tidyverse)
library(haven)
library(survey)
library(texreg)
library(car)Práctico 5: Regresión Lineal Múltiple con Muestras Complejas
¿Existe una brecha de ingresos por orientación sexual en Chile?
0. Objetivos del Práctico
La encuesta CASEN 2024 incorpora a escala nacional una pregunta sobre orientación sexual. Esto nos permite explorar si las personas no heterosexuales enfrentan una brecha de ingresos respecto a las personas heterosexuales en el mercado laboral chileno.
La pregunta de investigación parece simple, pero su respuesta no lo es: sin controles estadísticos, la brecha no es visible —e incluso podría parecer invertida—. Solo al aplicar Regresión Lineal Múltiple con svyglm() y controlar por educación, edad, sexo y territorio emerge la brecha real. Esto ilustra de manera directa el valor del control estadístico en ciencias sociales.
Al finalizar este práctico, podrás:
- Aplicar
survey::svyglm()con un diseño muestral específico para un subgrupo poblacional (expr_osig). - Interpretar cómo el control estadístico revela efectos que la estadística descriptiva oculta.
- Comparar coeficientes parciales para predictores continuos y categóricos a lo largo de modelos anidados.
- Calcular coeficientes estandarizados (Betas) e interpretar la magnitud relativa de cada predictor.
- Realizar diagnósticos básicos del modelo ajustado.
1. Preparación y Declaración del Diseño
Cargamos los paquetes y los datos. Los datos corresponden a la CASEN 2024, disponibles en el sitio del Ministerio de Desarrollo Social y Familia. La carga del archivo .RData y el renombramiento del objeto siguen el mismo procedimiento de los prácticos anteriores.
load("casen_2024.RData")
casen <- casen_20241.1 Preparación de variables
Seleccionamos las variables de interés e imponemos los filtros necesarios para trabajar con la submuestra de personas que respondieron la pregunta de orientación sexual, tienen ingreso laboral positivo y tienen información completa en todas las variables del modelo.
Una nota sobre el diseño muestral: CASEN 2024 incluye un factor de expansión específico (expr_osig) para la submuestra que respondió la pregunta de orientación sexual e identidad de género. Usar este ponderador en lugar del general (expr) produce estimaciones más adecuadas para este grupo poblacional.
casen_model_data <- casen %>%
select(
ytrabajocor, # Ingreso del trabajo (VD)
os1, # Orientación sexual
esc, # Años de escolaridad
edad, # Edad
sexo, # Sexo
region, # Región (para macrozona)
expr_osig, # Ponderador específico OS
varstrat, # Estrato de diseño
varunit # Unidad primaria de muestreo
) %>%
# Filtrar: os1 respondida y válida, expr_osig disponible, ingreso positivo
filter(
!is.na(os1), os1 > 0,
!is.na(expr_osig),
!is.na(ytrabajocor), ytrabajocor > 0
) %>%
# Crear factor de orientación sexual: Heterosexual vs. No heterosexual
mutate(
os_factor = factor(
ifelse(os1 == 1, "Heterosexual", "No heterosexual"),
levels = c("Heterosexual", "No heterosexual")
)
) %>%
# Sexo como factor (Hombre = referencia)
mutate(
sexo_factor = factor(sexo, levels = c(1, 2), labels = c("Hombre", "Mujer"))
) %>%
# Macrozona (Metropolitana = referencia)
mutate(
macrozona = case_when(
region %in% c(15, 1, 2, 3, 4) ~ "Norte",
region %in% c(5, 6, 7, 16) ~ "Centro",
region %in% c(8, 9, 14, 10, 11, 12) ~ "Sur",
region == 13 ~ "Metropolitana",
TRUE ~ NA_character_
),
macrozona = factor(macrozona, levels = c("Metropolitana", "Norte", "Centro", "Sur"))
) %>%
# Conservar solo casos completos en todas las variables del modelo
drop_na(ytrabajocor, os_factor, esc, edad, sexo_factor, macrozona,
expr_osig, varstrat, varunit)La muestra de trabajo cuenta con 57,664 casos: 56,009 personas heterosexuales y 1,655 no heterosexuales (2.9% del total).
1.2 Declaración del diseño muestral
Declaramos el diseño con el ponderador específico de orientación sexual (expr_osig) y las variables de estratificación y conglomerados estándar de CASEN.
casen_design <- svydesign(
ids = ~varunit,
strata = ~varstrat,
weights = ~expr_osig,
data = casen_model_data
)
casen_designStratified 1 - level Cluster Sampling design (with replacement)
With (12337) clusters.
svydesign(ids = ~varunit, strata = ~varstrat, weights = ~expr_osig,
data = casen_model_data)2. El Punto de Partida: Descriptivos por Orientación Sexual
Antes de modelar, exploramos las diferencias descriptivas entre grupos. Calculamos el ingreso medio y la escolaridad media por orientación sexual, usando el diseño declarado.
desc_os <- svyby(~ytrabajocor + esc + edad, ~os_factor, casen_design, svymean, na.rm = TRUE)
desc_osLas personas heterosexuales tienen un ingreso medio de $930,213 pesos, mientras que las no heterosexuales alcanzan $933,451 pesos. La diferencia bruta parece pequeña o incluso favorable a las personas no heterosexuales. Sin embargo, estas últimas tienen en promedio 15 años de escolaridad frente a 13.2 de las heterosexuales, y son considerablemente más jóvenes (33.3 vs 43.2 años). Estas diferencias en las características observadas ocultan la brecha estructural. El análisis de regresión permitirá separar estos efectos.
3. Regresión Lineal Simple: El Efecto Bruto
Ajustamos primero un modelo simple que solo incluye la orientación sexual como predictor, sin ningún control.
modelo_m1 <- svyglm(ytrabajocor ~ os_factor, design = casen_design)
htmlreg(modelo_m1,
custom.coef.names = c("Intercepto", "No heterosexual (ref. Heterosexual)"),
caption = "Tabla 1: RLS de Ingreso por Orientación Sexual (sin controles)",
caption.above = TRUE)| Model 1 | |
|---|---|
| Intercepto | 930213.43*** |
| (8516.32) | |
| No heterosexual (ref. Heterosexual) | 3237.61 |
| (30873.85) | |
| Deviance | 69959761187167056.00 |
| Dispersion | 1213252192691.45 |
| Num. obs. | 57664 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Interpretación (Tabla 1): El coeficiente para “No heterosexual” es $3,238 pesos (p = 0.92): prácticamente nulo y no significativo. Sin controlar por ninguna otra variable, la orientación sexual no predice el ingreso laboral. Esto no significa que no haya brecha —significa que la educación más alta de las personas no heterosexuales compensa su desventaja estructural, haciéndola invisible a nivel descriptivo.
4. Regresión Lineal Múltiple: El Control Estadístico Revela la Brecha
4.1 Controlando por escolaridad
Al controlar por años de escolaridad, aislamos el efecto de la orientación sexual sobre el ingreso para personas con el mismo nivel educativo.
modelo_m2 <- svyglm(ytrabajocor ~ os_factor + esc, design = casen_design)
htmlreg(list(modelo_m1, modelo_m2),
custom.model.names = c("Modelo 1: Sin controles", "Modelo 2: + Escolaridad"),
custom.coef.names = c("Intercepto", "No heterosexual (ref. Het.)", "Años de escolaridad"),
caption = "Tabla 2: Efecto de la orientación sexual antes y después de controlar por escolaridad",
caption.above = TRUE)| Modelo 1: Sin controles | Modelo 2: + Escolaridad | |
|---|---|---|
| Intercepto | 930213.43*** | -719610.43*** |
| (8516.32) | (29035.14) | |
| No heterosexual (ref. Het.) | 3237.61 | -217991.99*** |
| (30873.85) | (30432.11) | |
| Años de escolaridad | 124847.43*** | |
| (2615.51) | ||
| Deviance | 69959761187167056.00 | 58433661191223680.00 |
| Dispersion | 1213252192691.45 | 1013364916692.22 |
| Num. obs. | 57664 | 57664 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Interpretación (Tabla 2): Una vez controlada la escolaridad, el coeficiente para “No heterosexual” pasa a ser $-217,992 pesos (p < 0.001). La brecha, que en el Modelo 1 era invisible, emerge con claridad: personas no heterosexuales con el mismo número de años de estudio que sus pares heterosexuales ganan significativamente menos. El efecto de la escolaridad es $124,847 pesos por año adicional.
Este resultado ilustra un caso clásico de confusión por covariable: la ventaja educativa de las personas no heterosexuales enmascaraba su desventaja de ingresos.
4.2 Añadiendo la edad
modelo_m3 <- svyglm(ytrabajocor ~ os_factor + esc + edad, design = casen_design)
htmlreg(list(modelo_m2, modelo_m3),
custom.model.names = c("Modelo 2: + Esc", "Modelo 3: + Esc + Edad"),
custom.coef.names = c("Intercepto", "No heterosexual (ref. Het.)",
"Años de escolaridad", "Edad"),
caption = "Tabla 3: Incorporando edad como control adicional",
caption.above = TRUE)| Modelo 2: + Esc | Modelo 3: + Esc + Edad | |
|---|---|---|
| Intercepto | -719610.43*** | -1403559.50*** |
| (29035.14) | (52333.44) | |
| No heterosexual (ref. Het.) | -217991.99*** | -124970.14*** |
| (30432.11) | (29649.72) | |
| Años de escolaridad | 124847.43*** | 138137.82*** |
| (2615.51) | (2957.18) | |
| Edad | 11765.99*** | |
| (532.31) | ||
| Deviance | 58433661191223680.00 | 57107502567372008.00 |
| Dispersion | 1013364916692.22 | 990366484008.32 |
| Num. obs. | 57664 | 57664 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Interpretación (Tabla 3): Al agregar la edad, el coeficiente de orientación sexual se reduce a $-124,970 pesos, pero sigue siendo altamente significativo. Parte de la brecha del Modelo 2 se explicaba por la mayor juventud de las personas no heterosexuales (que aún no han acumulado el premio de experiencia laboral). Por cada año adicional de edad, el ingreso aumenta en promedio $11,766 pesos, controlando por escolaridad y orientación sexual.
4.3 Incorporando sexo y territorio: el modelo completo
modelo_m4 <- svyglm(ytrabajocor ~ os_factor + esc + edad + sexo_factor,
design = casen_design)
modelo_m5 <- svyglm(ytrabajocor ~ os_factor + esc + edad + sexo_factor + macrozona,
design = casen_design)
htmlreg(list(modelo_m3, modelo_m4, modelo_m5),
custom.model.names = c("M3: + Edad", "M4: + Sexo", "M5: Completo"),
custom.coef.names = c("Intercepto",
"No heterosexual (ref. Het.)",
"Años de escolaridad",
"Edad",
"Mujer (ref. Hombre)",
"Norte (ref. Metro)",
"Centro (ref. Metro)",
"Sur (ref. Metro)"),
caption = "Tabla 4: Modelos con controles completos",
caption.above = TRUE)| M3: + Edad | M4: + Sexo | M5: Completo | |
|---|---|---|---|
| Intercepto | -1403559.50*** | -1258721.85*** | -1111895.93*** |
| (52333.44) | (50442.37) | (46383.33) | |
| No heterosexual (ref. Het.) | -124970.14*** | -108302.01*** | -123944.49*** |
| (29649.72) | (29880.11) | (30063.10) | |
| Años de escolaridad | 138137.82*** | 139190.73*** | 135744.34*** |
| (2957.18) | (2947.72) | (2791.33) | |
| Edad | 11765.99*** | 11301.48*** | 11256.36*** |
| (532.31) | (529.60) | (523.06) | |
| Mujer (ref. Hombre) | -323102.15*** | -325284.89*** | |
| (12147.93) | (12162.98) | ||
| Norte (ref. Metro) | -133219.19*** | ||
| (15964.90) | |||
| Centro (ref. Metro) | -199438.05*** | ||
| (17551.66) | |||
| Sur (ref. Metro) | -183044.82*** | ||
| (15349.45) | |||
| Deviance | 57107502567372008.00 | 55635541622996280.00 | 55169596003094640.00 |
| Dispersion | 990366484008.32 | 964839526611.45 | 956759030974.71 |
| Num. obs. | 57664 | 57664 | 57664 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
Interpretación (Tabla 4):
Orientación sexual: La brecha se mantiene robusta a través de los modelos. En el modelo completo (M5), las personas no heterosexuales ganan en promedio $-123,944 pesos menos que las heterosexuales, controlando por escolaridad, edad, sexo y macrozona (p < 0.001). Esta persistencia refuerza la hipótesis de una desventaja estructural.
Sexo: Las mujeres ganan en promedio $325,285 pesos menos que los hombres, controlando por los demás factores. La brecha de género coexiste con la brecha por orientación sexual.
Macrozona: La Región Metropolitana presenta los ingresos estimados más altos. Las diferencias regionales son significativas y persistentes (Norte: $-133,219; Sur: $-183,045 respecto a la RM).
5. Comparando Efectos: Coeficientes Estandarizados (Betas)
Para comparar la magnitud relativa de los predictores continuos, estandarizamos la variable dependiente y los predictores numéricos antes de ajustar el modelo.
casen_model_data_z <- casen_model_data %>%
mutate(
ytrab_z = scale(ytrabajocor)[, 1],
esc_z = scale(esc)[, 1],
edad_z = scale(edad)[, 1]
)
casen_design_z <- svydesign(
ids = ~varunit,
strata = ~varstrat,
weights = ~expr_osig,
data = casen_model_data_z
)modelo_beta <- svyglm(ytrab_z ~ os_factor + esc_z + edad_z + sexo_factor,
design = casen_design_z)
htmlreg(modelo_beta,
custom.coef.names = c("Intercepto",
"No heterosexual (ref. Het.)",
"Beta Escolaridad (Z)",
"Beta Edad (Z)",
"Mujer (ref. Hombre)"),
caption = "Tabla 5: Coeficientes estandarizados (VD y predictores continuos en Z)",
caption.above = TRUE)| Model 1 | |
|---|---|
| Intercepto | 0.21*** |
| (0.01) | |
| No heterosexual (ref. Het.) | -0.11*** |
| (0.03) | |
| Beta Escolaridad (Z) | 0.56*** |
| (0.01) | |
| Beta Edad (Z) | 0.17*** |
| (0.01) | |
| Mujer (ref. Hombre) | -0.34*** |
| (0.01) | |
| Deviance | 62489.62 |
| Dispersion | 1.08 |
| Num. obs. | 57664 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Interpretación (Tabla 5): En unidades comparables:
- Escolaridad (β = 0.56): es el predictor con mayor impacto relativo sobre los ingresos. Por cada DE de aumento en escolaridad, el ingreso aumenta 0.56 DE.
- Edad (β = 0.17): efecto sustantivo pero claramente menor que el de la escolaridad.
- Orientación sexual (b = -0.115 DE): el coeficiente, aunque estadísticamente significativo, es menor en magnitud estandarizada que los de escolaridad y edad, lo que es coherente con una desventaja estructural real pero contenida.
6. Diagnósticos del Modelo (Material Complementario)
Evaluamos los supuestos del modelo completo (modelo_m5).
Linealidad (Residuos vs. Ajustados)
plot(modelo_m5, which = 1)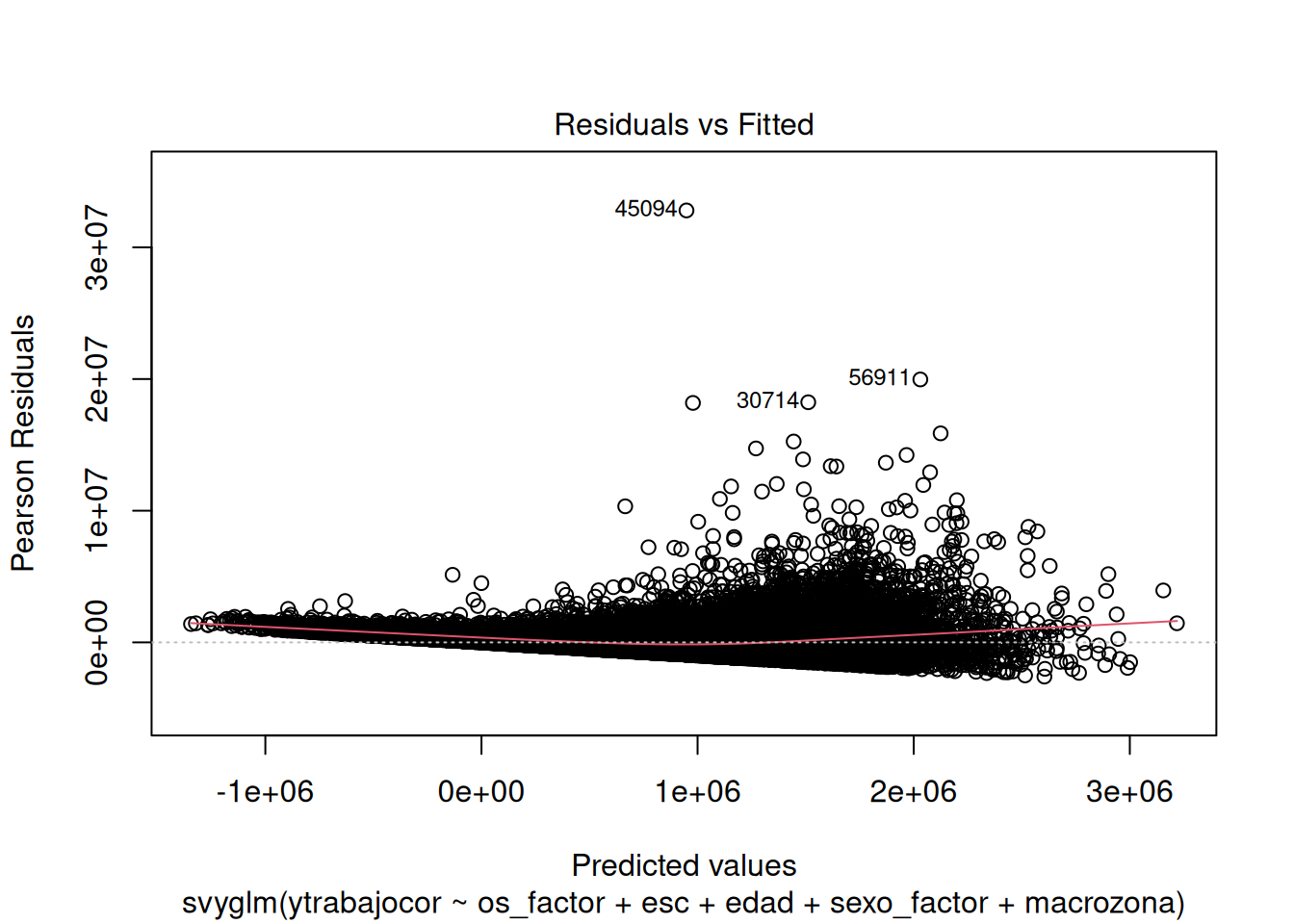
La línea LOESS es relativamente plana alrededor de cero, aunque quizás con una ligera tendencia al final. No se observan patrones curvos marcados; el supuesto de linealidad es razonablemente satisfecho, aunque podría existir alguna no linealidad leve no capturada por el modelo.
Homocedasticidad (Scale-Location)
plot(modelo_m5, which = 3)
La dispersión de los residuos aumenta con los valores ajustados, indicando heterocedasticidad: la varianza de los errores no es constante, sino que crece a medida que los ingresos predichos son más altos. Esto es esperable con datos de ingresos en Chile, donde la distribución salarial es muy asimétrica. La heterocedasticidad afecta la eficiencia de las estimaciones y la validez estricta de los errores estándar y p-valores calculados por defecto. svyglm() ya incorpora correcciones basadas en el diseño muestral que lo hacen más robusto que lm() en este sentido; sin embargo, en un análisis más avanzado se podría explorar una transformación logarítmica de los ingresos o el uso explícito de errores estándar robustos a la heterocedasticidad.
Normalidad de Residuos (Q-Q Plot)
plot(modelo_m5, which = 2)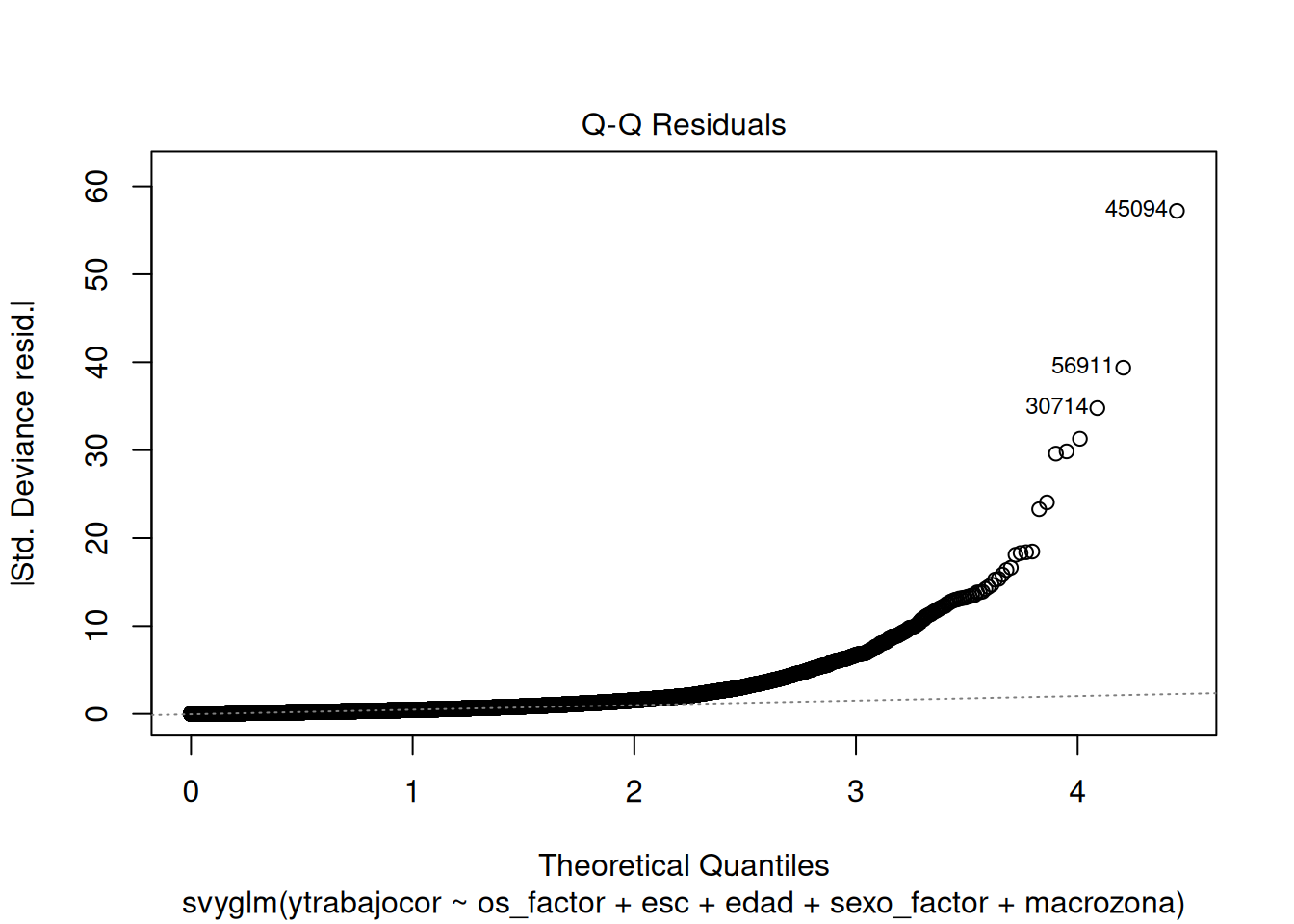
Los puntos se desvían marcadamente de la línea diagonal, en particular en la cola superior: la distribución de los residuos tiene una cola derecha mucho más larga de lo que esperaría una distribución normal (hay residuos positivos muy grandes, correspondientes a ingresos altos no bien predichos por el modelo). Esto refleja la distribución fuertemente asimétrica del ingreso laboral en Chile. Dado el gran tamaño muestral de este análisis, la inferencia sobre los coeficientes tiende a ser robusta a esta violación por el Teorema Central del Límite, aunque el hallazgo sugiere que el modelo podría mejorar con una transformación de la variable dependiente (por ejemplo, usando el logaritmo del ingreso).
Multicolinealidad (VIF)
car::vif(modelo_m5) GVIF Df GVIF^(1/(2*Df))
os_factor 1.081519 1 1.039961
esc 2.597234 1 1.611594
edad 1.960599 1 1.400214
sexo_factor 1.331770 1 1.154023
macrozona 1.347771 3 1.051000El GVIF máximo ajustado (GVIF^(1/Df), comparable a VIF) es 2.6. Todos los valores están por debajo del umbral problemático (comúnmente fijado en 5 o 10), lo que indica que los predictores no están excesivamente correlacionados entre sí. La multicolinealidad no representa un problema en este modelo y podemos interpretar los efectos parciales de cada predictor con relativa confianza.
Casos Influyentes
plot(modelo_m5, which = 5)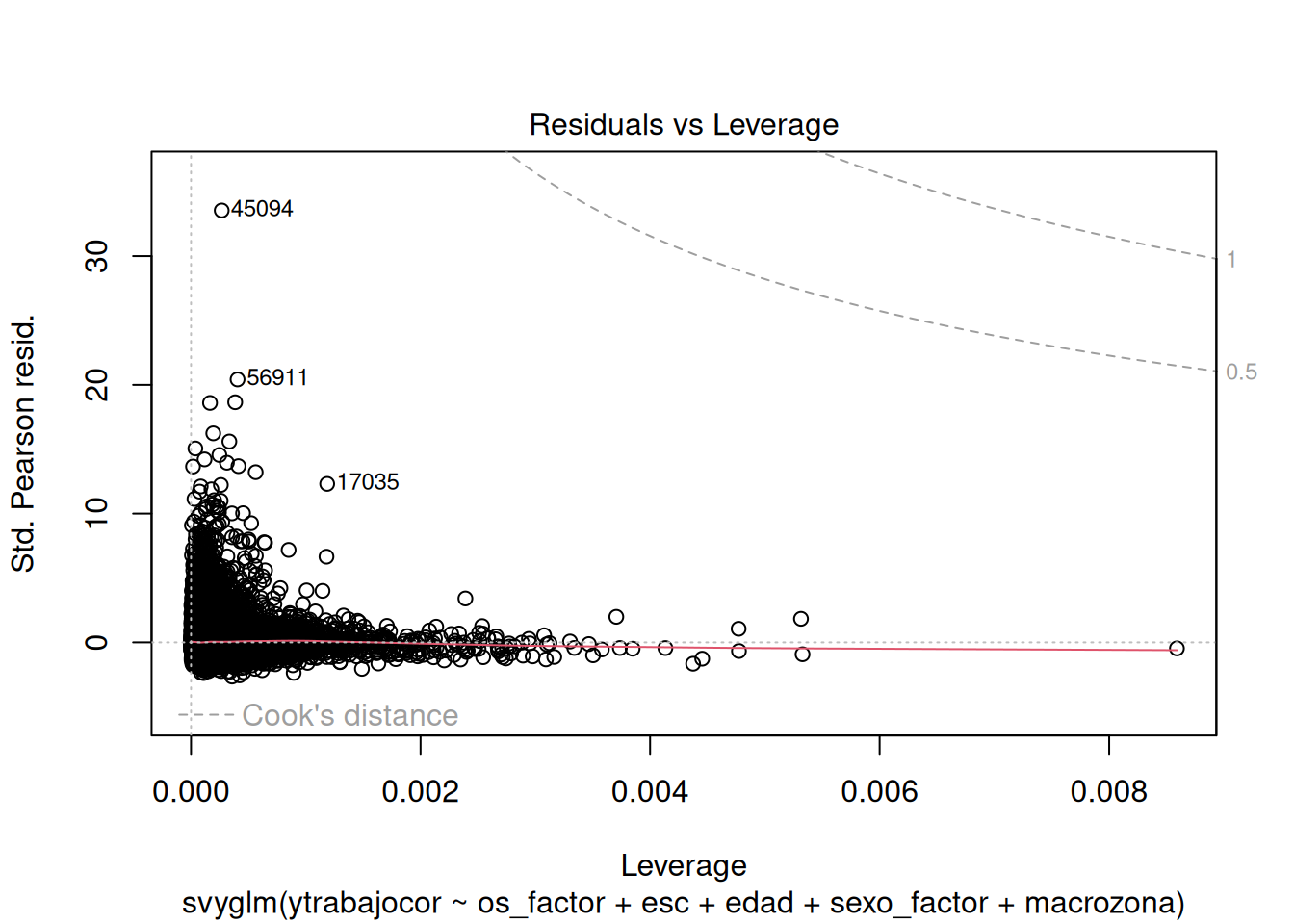
El gráfico muestra varios puntos con residuos estandarizados altos (lejanos a cero en el eje Y) y algunos con leverage moderado (eje X). Los puntos que combinan ambas características simultáneamente serían potencialmente influyentes. En este modelo no se observan casos que concentren residuos extremos y alto leverage al mismo tiempo, lo que sugiere que los coeficientes son estables. En un análisis más profundo, valdría la pena investigar los casos con residuos muy grandes para determinar si corresponden a valores atípicos genuinos o a errores en los datos.
7. Conclusión
En este práctico aplicamos Regresión Lineal Múltiple con diseño muestral complejo para responder una pregunta de investigación con relevancia social directa:
- Sin controles, la orientación sexual no predice el ingreso laboral: las personas no heterosexuales tienen educación y edad que compensan su desventaja.
- Al controlar por escolaridad, la brecha emerge con fuerza: personas no heterosexuales con igual nivel educativo ganan significativamente menos.
- La brecha es robusta a la incorporación de edad, sexo y territorio, lo que sugiere una desventaja estructural más allá de las diferencias en capital humano.
- El control estadístico —el aporte central de la RLM— fue la herramienta que permitió ver lo que la estadística descriptiva ocultaba.
Usamos además un diseño muestral específico (expr_osig), apropiado para la submuestra que respondió la pregunta de orientación sexual, ilustrando que el análisis de encuestas complejas puede requerir diseños distintos según la subpoblación de interés.
Visualización interactiva de correlación y regresión
La siguiente aplicación permite explorar visualmente cómo se ajusta una recta de regresión a una nube de puntos. Puedes acceder también directamente en: https://gabriel-sotomayor.shinyapps.io/rls_aad/.